유저 생존 곡선 그리기
 데이터분석가
데이터분석가
박장시
유저의 접속 세션 데이터를 활용하여, 유저의 생존 곡선을 그리고 수명을 측정한다.
문제 제기
이탈 예측하기에서는 유저의 이탈(churn)을 결과로만 다루었다. 즉, 이탈한 유저는 1로 표기하고, 이탈하지 않은 유저는 0으로 표기하여 결과가 2가지로만 나타나는 실험을 가정하였다. 이탈은 두 가지 결과로 요약할 수 있지만, 서비스 이용 시작부터 이탈까지의 과정은 유저마다 다르다. 특히, 유저가 얼마나 서비스를 이용하고 이탈하였는지, 그 시간을 측정하는 과정은 매우 중요하다. 유저의 이탈을 ‘죽음(death)’에 비유한다면 이탈까지의 시간은 유저의 ‘수명(lifetime)’이라고 할 수 있다.
유저의 수명을 결정하는 요소가 무엇인지 찾는 것은 서비스 개선에 결정적인 역할을 한다. 예를 들어, 특정 이벤트를 경험한 유저와 그렇지 않은 유저 사이에 유의미한 수명 차이가 나타난다면 해당 이벤트는 적극 권장해야 한다. 이처럼 유저의 어떤 특성이 수명에 영향을 미치는지 분석을 하기 위해서는 먼저 유저의 수명을 잘 측정해야 한다.
이를 합리적으로 측정하는 것은 추후 LTV(lifetime value)를 계산하는데도 필요하다. 간략하게 표현하면, 유저의 LTV는 유저의 수명(lifetime)과 가치(value)의 곱으로 표현할 수 있기 때문이다.
\[LTV = LT \times V\]따라서 돈과 시간을 함께 알아야 총 가치 계산이 가능하다. 아무리 돈을 많이 쓰는 고객이라도 빨리 죽으면(이탈이 빠르면) 가치는 낮다. 이 때문에 유저의 생존 시간을 측정한다.
생존 분석
생존 분석(survival analysis)은 특정 사건이 발생하는데 걸리는 시간을 다루는 분석 방법이다. 특정 사건은 ‘죽음’이나 ‘발병’ 등이 될 수 있으며, 시간은 특정 사건이 발생하기까지 걸린 시간을 의미한다. 만약 관심의 대상이 ‘죽음’이라는 사건이라면 시간은 ‘생존 시간’을 의미한다. 이런 사건을 통칭하여 실패(failure)라고 하며, 시간은 생존 시간(survival time)이라 한다. 반드시 의학 등에서만 사용하는 방법론은 아니며, 특정 사건이 발생하는 시간을 측정하는 과정에 범용적으로 활용한다.
생존 분석을 고객이나 유저 관점에 적용한다면, 이탈을 실패로 정의하고, 이탈하기까지의 시간을 생존 시간으로 정의할 수 있다. 유저가 서비스를 떠나면 서비스 입장에서는 유저가 죽었다고 볼 수 있으며, 이탈까지 걸린 시간이 유저의 생존 시간이다.
유저가 다시 돌아오는 경우도 생각할 수 있는데, 이 때는 관심의 대상인 사건이 2개 이상이므로 문제가 복잡해진다. 이러한 경우, 이탈은 죽음이 아니라 어떤 질병의 ‘재발(recurrence)’에 비유할 수 있다. 2개 이상의 사건을 다루는 문제에 대해서는 다른 글에서 소개하고, 이번 글에서는 단 하나의 사건만을 가정한다. 즉, 이탈한 유저는 다시 돌아오지 않고 죽는다.
유저의 생존 시간을 그림으로 나타내면 아래와 같다. 20주 전부터 관찰을 시작해 현재까지 유저의 생존 시간을 측정한다. 이탈의 기준을 어떻게 정할지는 이탈 기준 정하기를 참고한다.
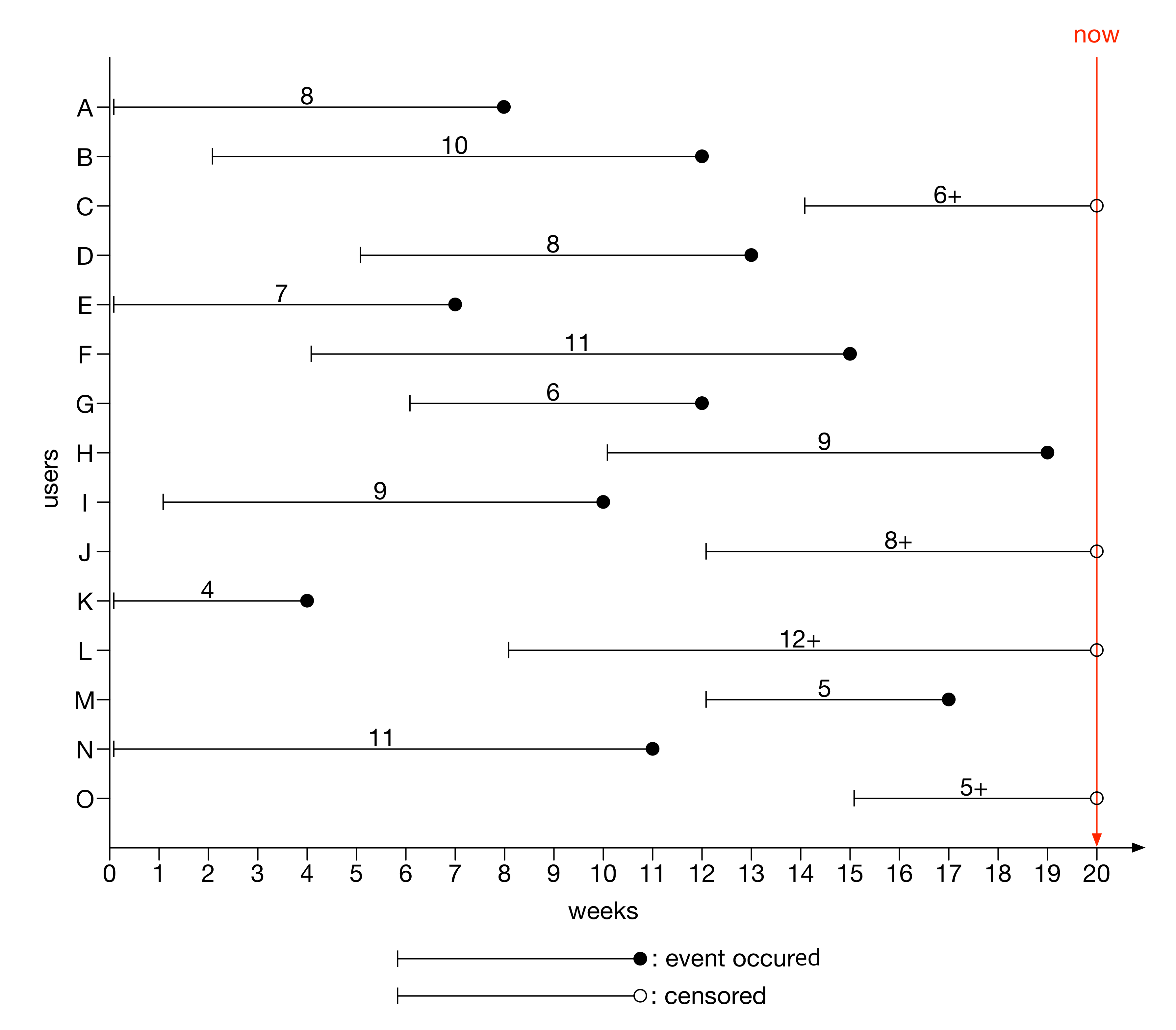
유저가 서비스 이용을 시작할 때, 유저의 수명이 시작되며 이 시점에 유저 수명 직선을 그리기 시작한다. 관찰 기간 동안에 유저가 이탈한 경우, 검은 원으로 유저 수명 직선을 마무리한다. 유저의 생존 시간은 직선의 길이와 같다. 반면에, 현 시점까지 이탈하지 않은 유저는 생존 시간이 얼마인지 정확하게 알 수 없다. 이를 중도 절단 자료(censored data)라고 한다. 이런 경우, 생존 시간을 완전하게 관찰할 수 없기 때문에 속이 빈 원으로 수명 직선을 마무리하고, 생존 시간 값 뒤에 (+)표시를 한다. 현 시점까지 생존한 C, J, L, O 유저가 이에 해당한다.
실제로 유저 J는 아래 그림처럼 24주에 이탈한다. 그러나 20주 시점에서는 이를 알 수 없으므로, 관찰된 생존 시간은 8주가 된다. (+)기호는 관찰된 생존 시간보다 더 긴 시간 동안 생존할 수 있다는 가능성을 나타낸다. 실제로 유저 J는 관찰된 생존 시간보다 4주를 더 살았으며, 실제 생존 시간은 12주다.
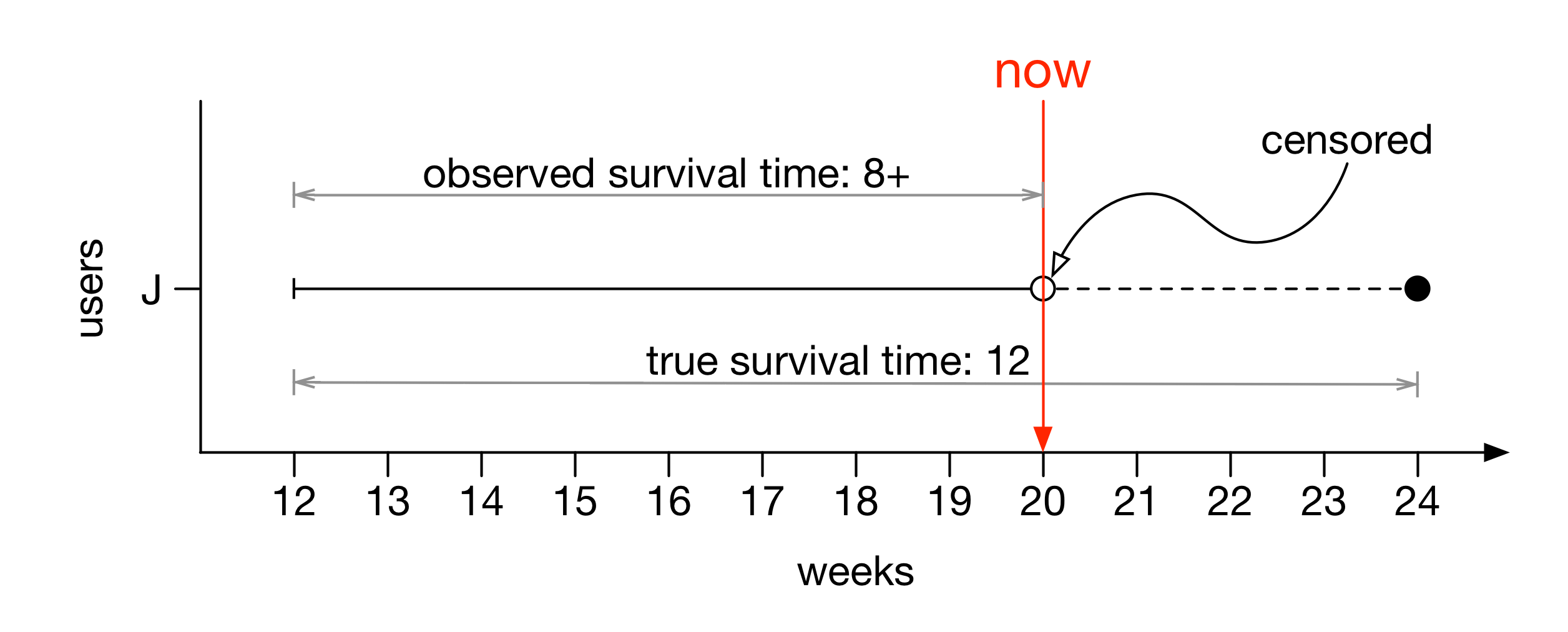
중도 절단된 생존 시간은 비록 불완전한 관찰 값이지만, 이를 아예 무시해서는 안된다. 관찰된 정보 만큼 분석에 활용한다. 다만, 이탈이 완전하게 관찰된 유저와는 구분을 두어 확률 계산에 반영한다. 이는 현 시점에 알고 있는 정보를 잘 활용하고자 노력하는 과정이다.
생존 함수와 생존 곡선
생존 시간 자료를 이용해 유저의 생존 확률을 계산할 수 있다. 생존 시간 $t$까지 유저가 생존할 확률은 아래와 같다. 이를 생존 함수(survival function)라 한다.
\[S(t) = P(T > t)\]- $T$: random variable for user’s survival time
- $t$: specific value for random variable $T$.
생존 함수를 그림으로 나타내면 일반적으로 아래와 같은 모양을 보인다. 이를 생존 곡선(survival curve)이라 한다. 생존 시간 $t$가 증가하면서 생존 확률 $S(t)$는 점점 감소한다. 이론적으로 생존 시간의 범위는 0부터 무한대이며, 생존 함수는 아래와 같은 값을 가진다.
- $S(0)=1$
- $S(\infty)=0$
즉, 시작 시점에 모든 유저는 생존해 있으며, 무한대 시간까지 생존하는 유저는 없다.
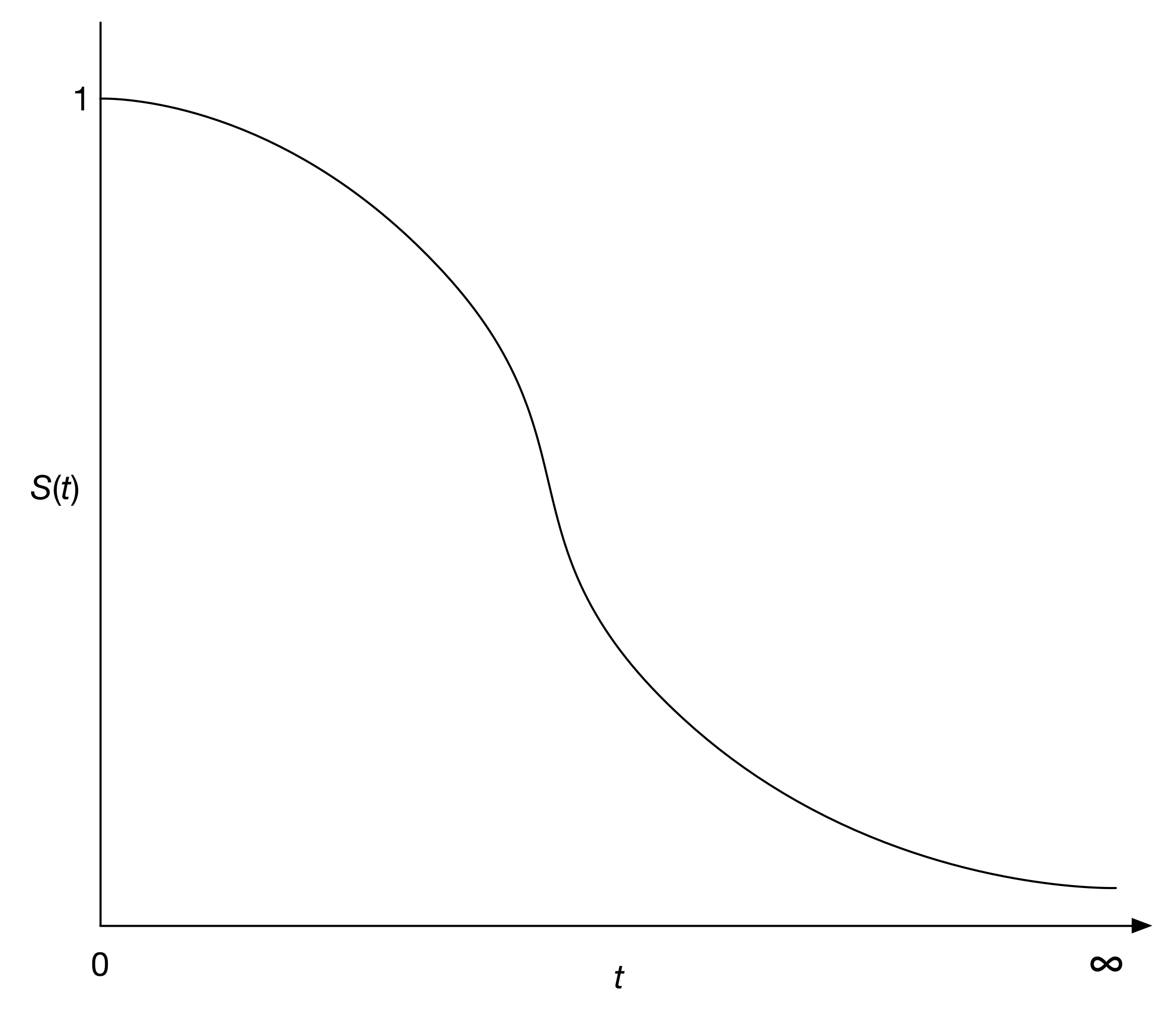
유저의 생존 곡선
유저의 생존 곡선을 그리기 위해서는 생존 시간 자료가 필요하다. 이는 일반적인 접속 세션 데이터를 가공하여 만들 수 있다. 위에서 예시로 든 유저 A~O 데이터에 일부 유저를 더해서 예시 데이터를 만들었다. 예시로 만든 유저의 생존 시간 자료는 아래와 같다. churn=1인 유저는 관찰 기간 동안 실제로 이탈 사건이 일어난 유저다. churn=0인 유저는 실제 이탈을 관찰하지 못한 유저다. 즉, censored data다.
n uid time churn
1 A 8 1
2 B 10 1
3 C 6 0
4 D 8 1
5 E 7 1
6 F 11 1
7 G 6 1
8 H 9 1
9 I 9 1
10 J 8 0
11 K 4 1
12 L 12 0
13 M 5 1
14 N 11 1
15 O 5 0
. . . .
. . . .
. . . .
26 Z 6 0
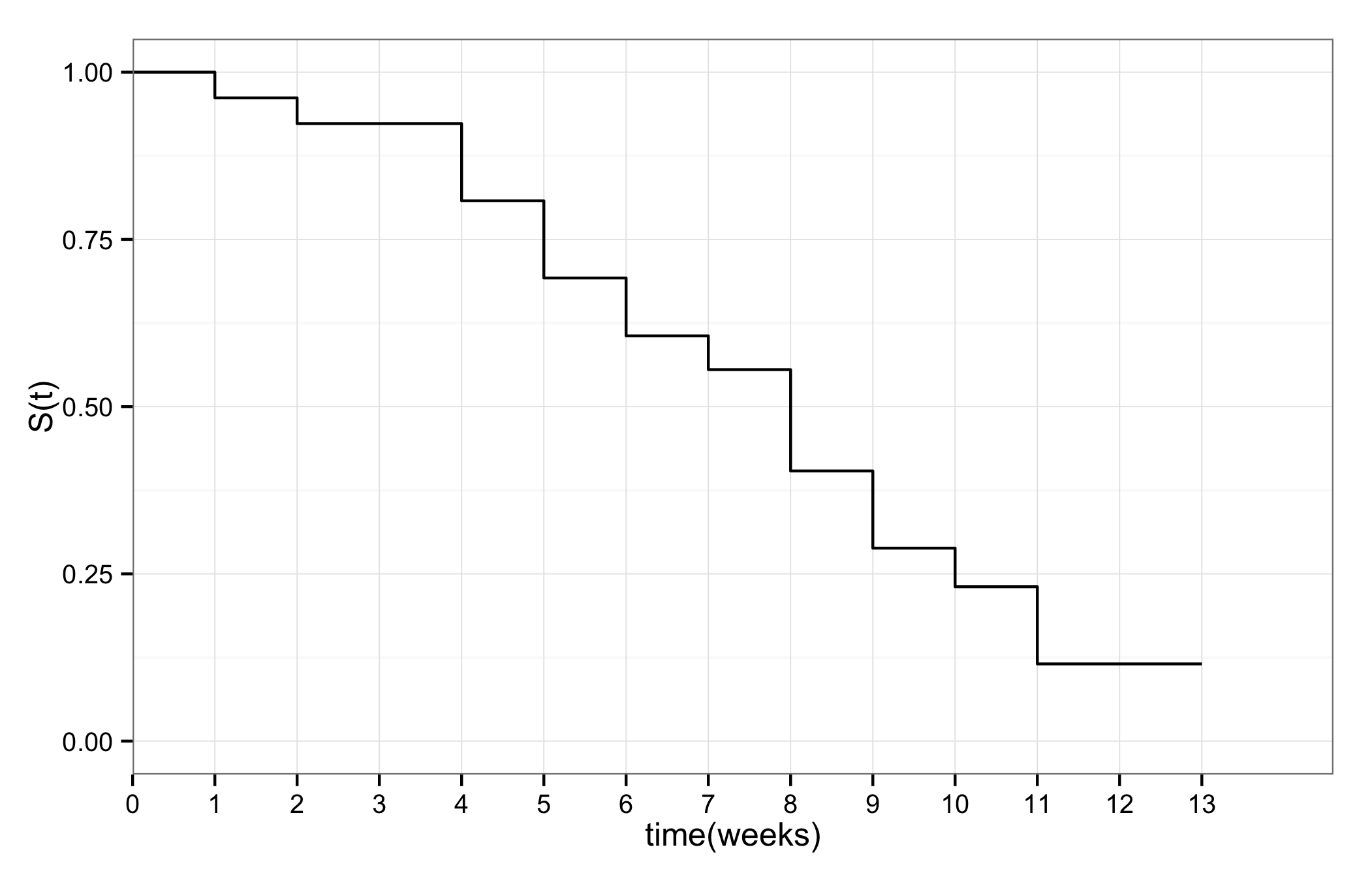
실제 데이터로 유저의 생존 곡선을 그리면 아래와 같다. 생존 함수 추정은 카플란-마이어 추정량(Kaplan-Meier estimator)을 이용한다. 이론적인 생존 곡선과는 다르게 계단형 곡선을 볼 수 있다. 생존 곡선을 보면 절반의 유저가 이탈하는데 약 8주가 걸리는 것을 알 수 있다.
#### survival_example.R
# load packages
library(survival)
library(ggplot2)
# read data
uid <- LETTERS
time <- c(8, 10, 6, 8, 7, 11, 6, 9, 9, 8, 4, 12, 5, 11, 5, 1, 2, 13, 5, 6, 8, 5, 4, 4, 5, 6)
churn <- c(1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0)
surv_df <- data.frame(uid, time, churn)
# make survival data
surv_obj <- Surv(surv_df$time, surv_df$churn)
# draw survival curve
fit <- survfit(surv_obj ~ 1)
fit_df <- data.frame(time = c(0, fit$time), surv = c(1, fit$surv))
ggplot(fit_df, aes(x=time, y=surv)) +
geom_step() +
ylab('S(t)') +
xlab('time(weeks)') +
ylim(c(0, 1)) +
scale_x_continuous(breaks=seq(0, 13, 1)) +
theme_bw()서로 다른 그룹의 비교
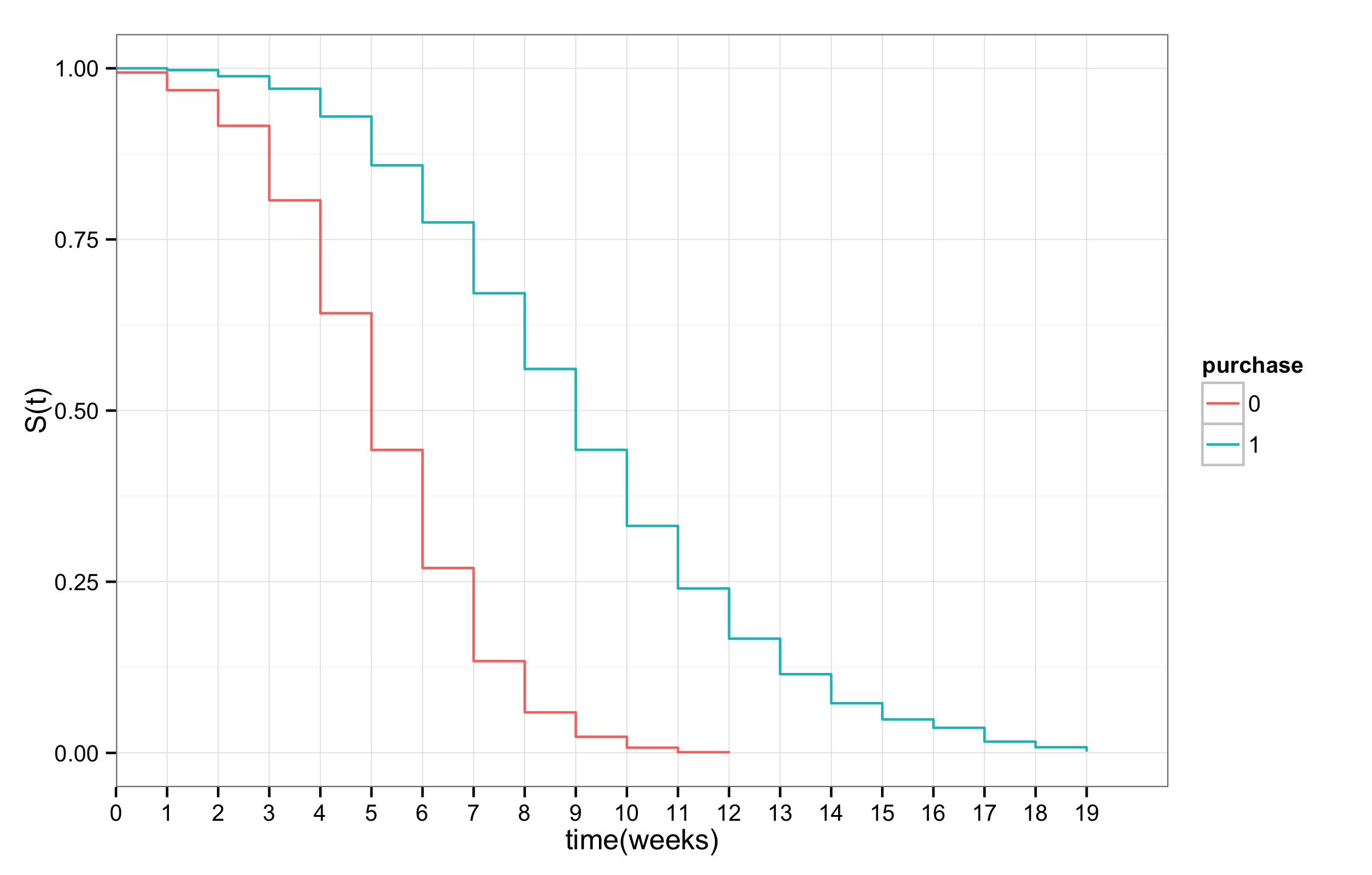
유저 그룹에 따라 생존 곡선을 그리면, 그룹 간의 차이를 관찰할 수 있다. 예를 들어, 구매 유저 그룹(purchase=1)과 비구매 유저 그룹(purchase=0) 사이의 생존 곡선을 그리면 아래와 같다. 확연하게 구매 유저의 생존 확률이 높다. 통계적으로 두 그룹의 생존 곡선에 차이가 있는지 확인하려면 로그-랭크 테스트(log-rank test)를 수행한다.
활용안
변수 변경
생존 함수, $S(T)=P(T>t)$에서 $T$는 관찰 시간이다. 만약, 이를 시간과 대체할 수 있는 변수로 바꾸면 새로운 분석이 가능하다. 예를 들어, RPG 게임의 캐릭터 레벨을 x축으로 바꾸면 레벨에 따른 생존 곡선을 그릴 수 있다. 이를 통해 어느 레벨에서 가장 많은 유저들이 이탈하는지 파악이 가능하다. 시간이 흐르면서 변화하는 진행 척도(progress measure)는 무엇이든 대입 가능하다. 스테이지형 게임이라면 스테이지를 x축으로 바꿀 수 있고, 웹 페이지라면 유저 경로 흐름(user pass flow)을 x축으로 사용할 수 있다.
유저 그룹도 다양하게 설정 가능하다. 위의 예시에서는 구매 유저 그룹과 비구매 유저 그룹의 생존 곡선을 비교하였다. 다른 예로, 특정 이벤트에 참여한 유저와 그렇지 않은 유저의 생존 곡선을 비교하여 이벤트의 성패를 가늠할 수 있다. 어떤 퀘스트를 완료한 유저와 그렇지 않은 유저, 특정 비디오를 시청한 유저와 그렇지 않은 유저의 생존 곡선도 비교 가능하다. 만약 유저의 서비스 시작 날짜를 기준으로 그룹을 나누면, 웹 분석에서 흔히 수행하는 코호트 분석(cohort analysis)을 더 상세하게 할 수 있다.
설명 변수 추가
어떤 변수가 수명에 영향을 주는지 분석할 수 있다. 예를 들어, 구매 유저의 수명이 길다는 것을 알았다면, 많이 구매한 유저가 적게 구매한 유저보다 수명이 더 긴지 궁금해진다. 단순히 구매-비구매 비교에 그치지 않고, 구매 액수가 생존 시간에 미치는 영향을 파악할 수 있다. 이외에도 다양한 설명 변수의 영향을 평가할 수 있다. 이 방법에 대해서는 설명 변수를 이용하여 유저 생존 곡선 그리기에서 소개한다.
이벤트 변경
위에서는 유저의 이탈을 유저의 죽음으로 취급하여 분석하였다. 그러나 반드시 부정적인 사건을 관심의 대상으로 삼아야 하는 것은 아니다. 만약 유저의 첫번째 구매를 관심의 사건으로 삼는다면, 첫 구매까지 걸리는 시간이 얼마나 걸리는지 분석할 수 있다. 이 경우에는 최대한 짧은 시간 동안 많은 유저가 첫 구매 사건을 기록하는 것이 더 좋은 의미를 갖는다. 어떤 사건이 벌어지기까지의 시간을 분석할 수 있으므로 다양한 상황에 대입할 수 있다.
위험 추정
생존 곡선을 그릴 수 있으면, 각 시각에서의 위험률을 계산할 수 있다. 위험 함수(hazard function)을 도출하면, 유저들이 어느 시점에 가장 이탈할 가능성이 높은지 위험(failure rate) 관점에서 살펴볼 수 있다. 단순하게 설명하면, 많이 죽는 시각이 가장 위험한 시각이다. 추후에 다른 글에서 살펴본다.
LTV, 돈과 시간 측정
유저의 가치를 평가하기 위해서는 유저가 얼마나 오래 서비스를 이용할 것인지 알아야 한다. 단위 시간당 가치를 유저의 생존 곡선과 결합해야 유저의 총 가치가 어느 정도인지 알 수 있다. 가치의 평가 방식에 따라 달라지겠지만, 유저의 총 가치는 생존 곡선의 면적에 비례할 것이다.
단위 시간당 가치의 평가 자체도 유저의 생존 시간과 밀접하게 관련이 있다. 사람의 일생에서 나이에 따른 소비 패턴이 있는 것처럼, 유저에게도 시간에 따른 소비 패턴이 있다. 이를 제대로 평가하려면 유저의 생존 시간 측정이 필요하다.
매출 증대를 위해서 유저의 시간당 가치를 올리는 것도 좋겠지만, 유저의 수명을 늘리는 전략도 유효하다. 무리한 매출 전략이 유저의 수명을 단축시킨다면 오히려 총 기대 가치는 감소한다. 반대로, 유저의 수명을 증가시킬 수단이 없다면 시간당 가치 증대에 자원을 투입하는 것이 현명할 것이다. 이와 같은 의사결정을 위해서 돈과 시간에 대한 측정이 함께 필요하다.
관련 글
다음 글: 설명 변수를 이용하여 유저 생존 곡선 그리기
참고
- John P. Klein, Melvin L. Moeschberger(1997), Survival Analysis: Techniques for Censored and Truncated Data, Springer
- http://en.wikipedia.org/wiki/Survival_analysis
- http://en.wikipedia.org/wiki/Kaplan%E2%80%93Meier_estimator
- http://www4.stat.ncsu.edu/~dzhang2/st745/chap2.pdf