이탈 기준 정하기
 데이터분석가
데이터분석가
박장시
(이 글은 Box and Whisker 홈페이지와 datum.io에 중복으로 게재되었습니다.)
데이터 관점에서의 이탈
‘이탈(churn)’의 기준을 어떻게 설정해야하는지 큰 고민 없이 정하는 경우가 많다. 보통 실무자의 주관에 따라 정해지는데, 이것이 꼭 틀린 것은 아니다. 예를 들어, 일주일에 한번씩 업데이트가 있는 게임이라면 서비스 담당자의 직관으로 일주일 이상 접속하지 않는 유저를 이탈 유저로 정의할 수 있을 것이다. 다만, 이탈의 정의를 데이터 관점에서 검토할 수 있다면 더 객관적인 이탈 기준을 확보하고 더 나은 이탈 사용자 관리가 가능하다.
좋은 이탈 기준의 조건
좋은 이탈 기준의 조건으로 2가지를 생각할 수 있다.
-
최대한 빨리 이탈을 탐지한다.
사용자가 서비스에서 이탈했는지 구분하는 이유는 이에 대한 대응을 빨리 하려는 목적이 크다. 마지막 접속이 1년을 넘은 사용자를 이탈 유저로 정의한다면, 이탈의 확실성은 크지만 이 정보를 통해서 할 수 있는 일이 없다. 1년 전에 마지막으로 접속한 유저에게 이제와서 서비스에 돌아오라고 이야기해도 소용없는 일이다. 이런 경우에는 고객 재확보(reacquisition) 전략이 필요하며, 통상적인 이탈 유저 관리와는 다르다.
-
최대한 확실한 이탈을 탐지한다.
빨리 이탈을 탐지하기 위해서 마지막 접속이 하루만 지나도 이를 이탈 사용자로 정의한다면, 이탈 가능성이 낮은 사용자도 이탈 유저로 분류하게 된다. 이탈 사용자를 관리하기 위해서는 비용이 들어가기 마련이며, 이탈 가능성이 낮은 유저에게 이탈 관리를 한다면 자원을 낭비하게 된다. 따라서, 이탈 가능성이 높은 사용자를 이탈 유저로 구분할 수 있는 적절한 기준이 필요하다.
위의 두 가지 조건을 종합하면, (1)가장 빨리 이탈을 탐지할 수 있으면서도 (2)이탈 가능성을 어느 정도 담보할 수 있는 이탈 정의가 필요하다. 이를 위해서 사용자의 접속 세션 데이터를 활용하여 어떤 이탈 기준이 적절한지 탐색한다.
기본 가정
데이터를 직접 보기 전에 몇 가지 가정이 필요하다. 우선 사용자의 접속 세션 데이터는 일별 기록을 기준으로 한다. 즉, 하루에 몇 번 접속했던지 상관없이 해당 날짜에 한번이라도 접속했다면 접속 세션 로그를 기록한다. 따라서, 이 글에서 논의하는 이탈 기준은 일 단위가 된다. 시간 단위의 접속 세션 데이터를 활용하면 더 많은 분석 결과를 얻을 수 있으나, 논의를 간단하게 하기 위해서 생략한다.
완전한 이탈의 기준은 100일로 정한다. 즉, 마지막 접속이 100일을 지난 사용자는 고객 재확보 캠페인 등이 없을 경우에는 다시 돌아올 가능성이 아주 희박하다고 본다. 이는 서비스의 특성에 따라서 다른데, 특별한 이벤트가 없어도 100일 전에 마지막으로 접속했던 사용자들이 재접속하는 경우가 많다면 이 기준은 확장되어야 한다. 이는 기본적인 집계 작업으로 측정이 가능하므로 서비스 특성에 맞도록 조정할 수 있다.
해결해야할 문제
우리가 데이터를 통해서 대답해야할 문제를 요약하면 다음과 같다. 마지막 접속이 100일을 넘은 사용자는 특별한 이벤트가 없으면 재접속할 가능성이 거의 없다. 그러나 100일동안 사용자가 접속을 안 하는 사이에 아무것도 하지 않고 이탈 여부를 관찰만 하면서 기다릴 수는 없다. 따라서 100일보다 더 짧은 시간 단위의 이탈 기준이 필요하다. 다만, 이 짧은 시간 단위의 기준을 통해서 실제 이탈 가능성이 높은 사용자를 걸러낼 수 있어야 한다.
간단한 비유를 들면, 더 쉽게 이해가 가능하다. 100개 단위로 포장되는 과자 세트가 있는데, 특이하게도 과자가 100개의 작은 상자에 담겨서 일렬로 개별 포장되어 있다. 100개의 개별 포장 안에 과자가 실제로 들어있는지는 모른다. 다만, 100개가 모두 비어 있는 과자 세트는 문제가 되기 때문에 이를 가능한 빨리 찾는 것이 중요하다. 이를 위해서 과자 포장을 처음부터 차례대로 뜯어볼 수 있는데, 과연 몇 개까지 뜯어서 확인을 하면 과자 세트 전체가 비었다고 결론내릴 수 있을까.
데이터로 확인하기
과거 100일 동안의 사용자 접속 세션 자료가 있다면, 어떤 사용자가 실제 이탈하였는지 알 수 있다. 이를 토대로 세션 자료에서 처음 며칠을 확인하면 이탈로 판단할 수 있는지 확인이 가능하다. 아래 그림에서 적절한 n을 찾기 위해 n을 변경하며 이탈 비율을 계산할 수 있다.
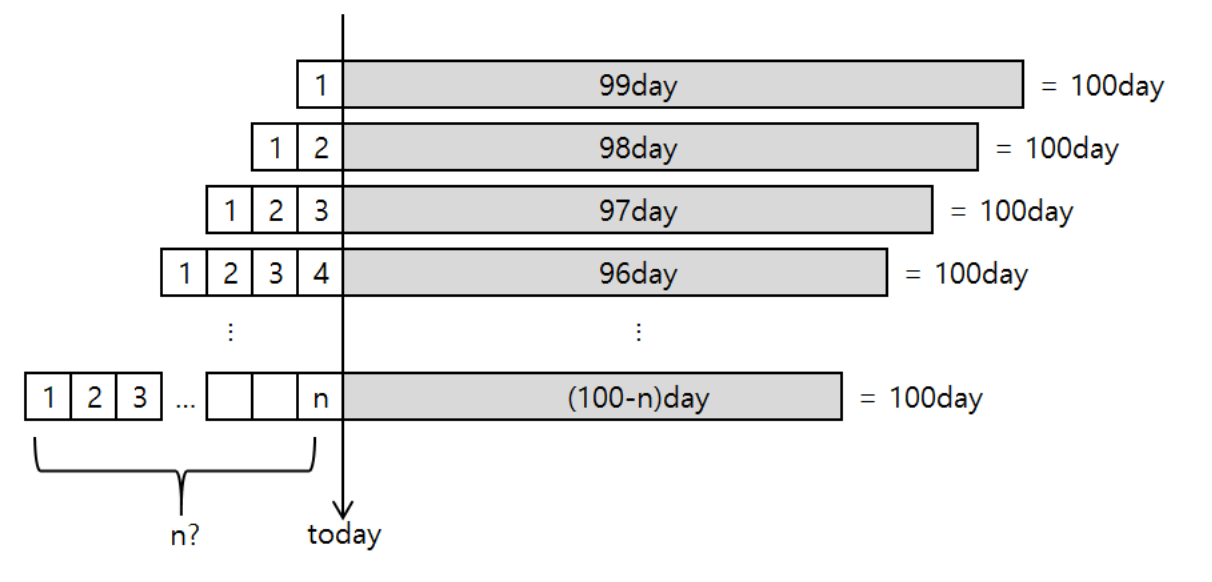
초반 n일 동안의 접속 일수가 0일 경우에 사용자가 이탈할 확률 \(p(churn = 1|count.days_{n}=0)\)의 추이를 n의 변화에 따라 관찰하면 적절한 n의 값을 정할 수 있다.
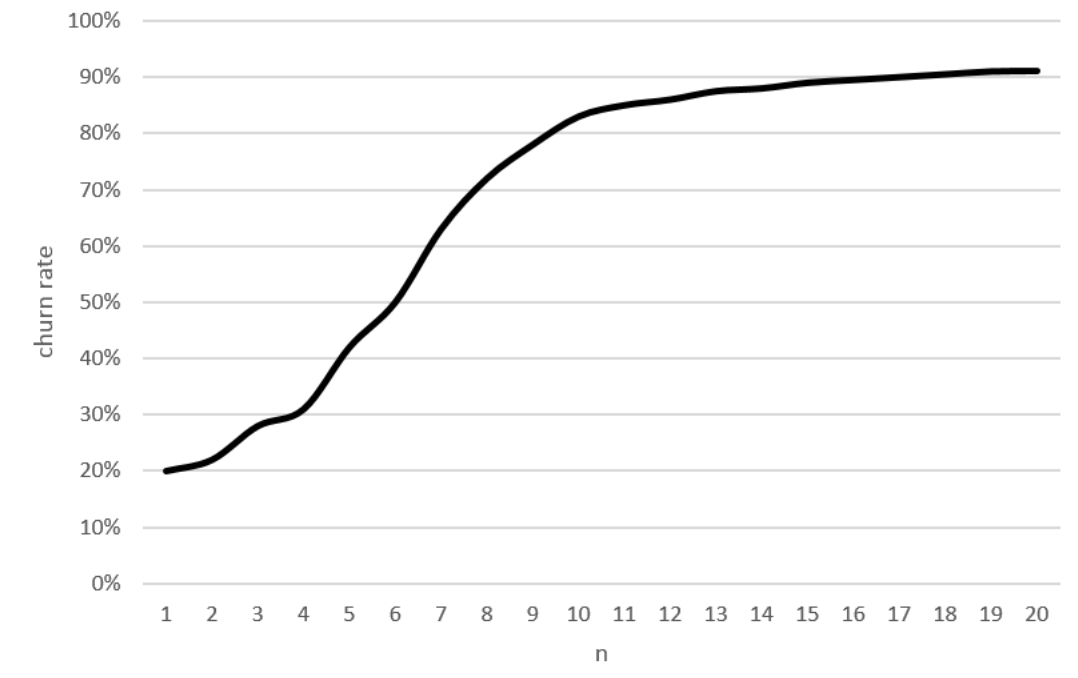
위의 그래프는 가상의 접속 자료를 토대로 계산한 것이다. n이 커지면서 이탈 비율도 증가하는 것을 알 수 있다. 관건은 어느 정도의 n에서 관찰 기간의 증가를 멈추고 이탈 기준으로 정할 것인지 결정하는 문제다. n이 작으면 이탈 여부를 빨리 알 수 있지만 이탈이 불확실한 사용자를 다수 이탈로 분류하게 된다. n이 크면 이탈 가능성이 확실한 사용자만을 걸러낼 수 있지만, 이미 이탈한 유저들에 대한 대응이 늦어진다.
만약 오분류의 위험성을 감수하더라도 이탈 가능성이 있는 사용자에 대해서 빠른 대응을 원한다면 n을 줄이는 것이 타당하다. 반면에 매우 고비용의 사용자 관리 정책을 기획하고 있다면, 약간 대응 시간이 늦더라도 더 정확한 이탈 기준을 위해 n을 늘리는 것이 적절하다.
생각할 문제
위와 같은 방식으로 이탈 기준을 정의하면 기존의 데이터를 참고해서 의사결정을 내릴 수 있는 장점이 있다. 다만 몇 가지 문제가 있는데, 우선 관찰 시점을 언제로 하느냐에 따라 결과가 달라질 수 있다. 요일이나 계절에 따른 차이가 존재할 수 있으므로 이에 대해 충분히 고려해야 한다. 요일에 따른 차이를 따로 검토해보고, 월별 자료나 서비스 특성에 따른 특수한 시기에 대해서도 비교가 필요하다.
개별 사용자의 행동 특성을 고려하지 않는다는 것도 문제점이다. 어떤 사용자는 서비스 접속을 아주 드물게 할 수도 있고, 어떤 사용자는 매일 접속할 수도 있다. 이렇게 서로 다른 행동 특성을 가진 사용자들에게 일괄적인 기준을 제시하는 것은 문제가 될 수 있다. 따라서 개별 사용자의 행동 특성을 고려한 이탈 기준이 필요하다. 개별 사용자를 고려한 이탈 측정하기에서는 이런 문제점을 고려한 이탈 기준에 대해서 살펴본다.