구글 애널리틱스 API를 이용한 캠페인 분석(2)
 데이터분석가
데이터분석가
박장시
다차원 큐브에서 원하는 기준의 셀을 뽑아내는 것은 그래프 데이터 구조에서 최단 경로 탐색에 비유할 수 있다. 간단한 그래프 탐색 알고리즘을 설명하고, 이를 어떻게 다차원 큐브 탐색에 응용하였는지 살펴본다. 이를 통해 ‘캠페인 분석기’가 어떻게 잠재 성과가 높은 세그먼트를 찾는지 설명한다.
가장 성과가 높은 고객 세그먼트 찾기
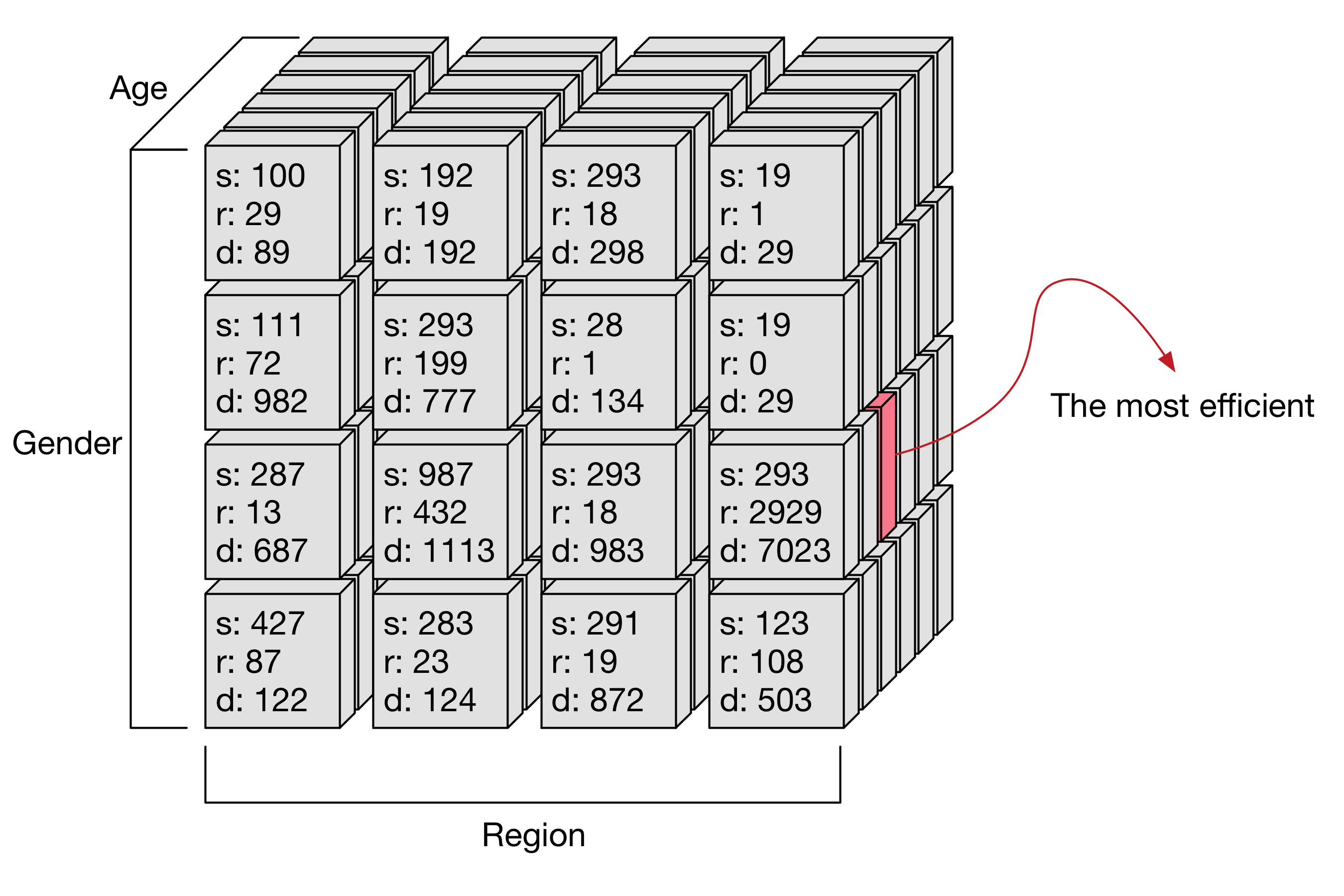
마케팅 담당자는 여러가지 프로모션 후에 어떤 고객이 가장 반응을 많이 했는지 알고 싶어한다. 예를 들어, 특정 광고를 보고 어떤 고객들이 가장 많이 유입되었고 매출을 일으켰는지 궁금하다. 수도권에 사는 20대 여성 중, 신규 고객이면서 아이폰을 사용하고 자동차와 팝 음악에 관심이 높은 고객이 특정 광고에 반응했다는 사실을 알고 싶다. 만약 모든 고객의 웹 로그와 취향 정보 등을 데이터베이스에 저장하고 있다면 이런 정보를 얻는 것은 비교적 쉬운 일이다. 이미 기존의 DW 시스템에서 고객을 구분 지을 수 있는 다차원 조합을 잘 구조화시켜 저장한다면 간단한 쿼리로 조회가 가능하다.
구글 애널리틱스 활용하기
문제는 이런 웹 로그를 다 저장하고 처리하기 위한 시스템을 미리 갖추어야 한다는 점이다. 게다가 고객의 취향 정보는 단순히 웹 로그만 다 저장한다고 알 수 있는 데이터가 아니다. 만약 구글 애널리틱스(Google Analytics, 이하 GA)를 잘 활용하고 있다면 GA의 자원을 이용해 데이터를 활용할 수 있다. 굳이 직접 웹 로그를 수집하지 않더라도 데이터 수집, 저장, 연산, 인출을 GA에게 대신 시킬 수 있다.
GA는 Reporting API를 통해서 저장하고 있는 데이터를 손쉽게 인출할 수 있도록 돕는다. GA가 제공하는 웹 기반 인터페이스는 이미 어떻게 데이터를 보여줄지 결정된 부분이 많아서 자유로운 데이터 탐색에 제약이 생긴다. 그러나 Reporting API를 사용하면 이러한 제약없이 데이터를 자유롭게 살펴볼 수 있다. 최대 7개의 차원 조합에 대해서 10가지 종류의 수치를 한 번의 API 호출로 얻을 수 있다.
더 나은 API 호출 방법
GA에서 관심 있는 차원이 20개라고 가정하면, 이를 통해 만들어지는 차원의 조합 수는 약 13만 개가 된다.
\[\sum_{r=1}^7 \binom{20}{r} = 137,979\]단순히 생각하면 GA Reporting API를 13만 번 호출해서 데이터를 모두 저장하고 여기서 원하는 데이터를 추출하거나 탐색하면 된다. 그러나 GA Reporting API 사용에는 제약이 따른다. 1초에 10개의 호출만 가능한데, 13만 개의 호출을 꾸준히 보낸다고 하면 약 2시간의 시간이 소요된다. 게다가 결정적으로 하나의 GA view 마다 하루에 10,000 개의 호출만 보낼 수 있다. 따라서 API를 이용해서 모든 데이터를 수집하는 것은 불가능하댜.
더 똑똑한 방법으로 API를 호출하고 데이터를 탐색할 필요가 있다. 다행히 API 호출을 하면 호출 결과를 바로 알 수 있다. 한 번의 API 호출 후에, 그 결과를 참고해서 다음 호출을 선택적으로 결정할 수 있다. 현재까지 호출한 모든 데이터를 참고하면 다음 호출은 어느 차원 조합에 대해 하는 것이 합리적인지 결정할 수 있으며, 이는 그래프 탐색과 매우 유사하다. 다차원 큐브를 만들지 않고 그래프 탐색을 이용하면, 주어진 제약 조건에서 최선의 결과를 얻도록 노력할 수 있다.
그래프 탐색 알고리즘
그래프 탐색에는 여러 가지 종류가 있는데 그 중에서도 Best-first search를 사용한다. 흔히 길 찾기 문제에서 활용하는데, 아래의 예제를 보면 가장 거리가 짧은 길을 찾아 원하는 노드로 도착하는 것이 알고리즘의 목표다. ‘Best-first’라는 말에서 알 수 있듯이 다음 탐색할 노드를 결정할 때, 가장 우선 순위가 높은 노드를 선택한다. 최단 거리 길 찾기 문제라면 가장 짧은 거리를 갖는 노드가 가장 우선 순위가 높은 노드가 된다.
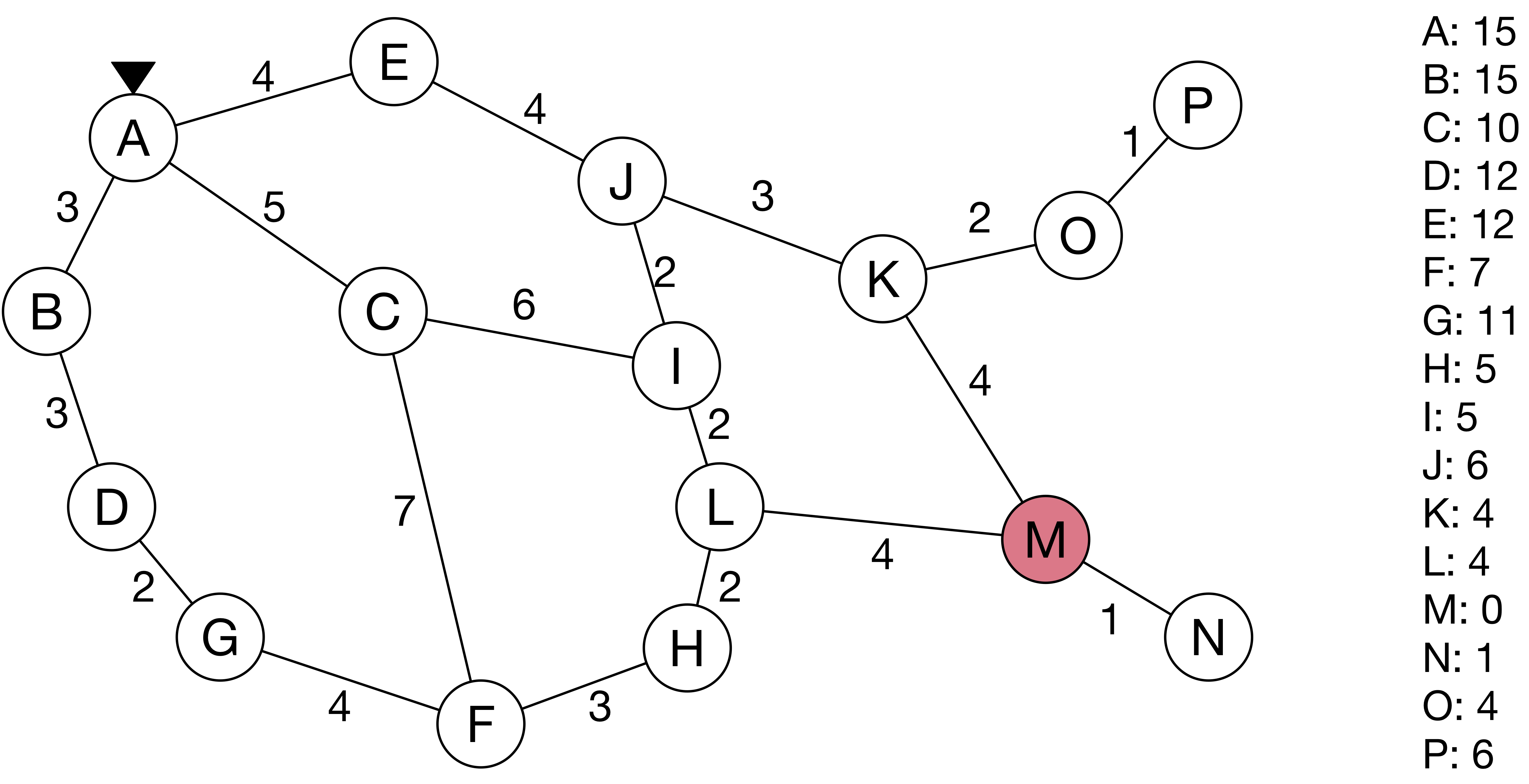
A에서 출발한다.
목표는 M까지 최단 거리로 도달하는 것이다.
우선 순위는 각 노드를 방문할 때마다 알 수 있는 이웃 노드와의 실제 거리(그래프 링크 위의 숫자)와 각 노드에서 목표 노드 M까지의 직선 거리(그림 오른쪽 숫자 리스트)를 이용한다.
예시를 위해서 그래프 구조를 모두 볼 수 있도록 나열하지만, 노드 A에서 출발하는 컴퓨터(검은색 역삼각형)는 실제로 그래프 구조를 전혀 모른다.
흡사 스타크래프트의 SCV가 안개 낀 게임 지형에서 정찰을 통해 적 진지를 빨리 탐색하려는 시도와 같다.
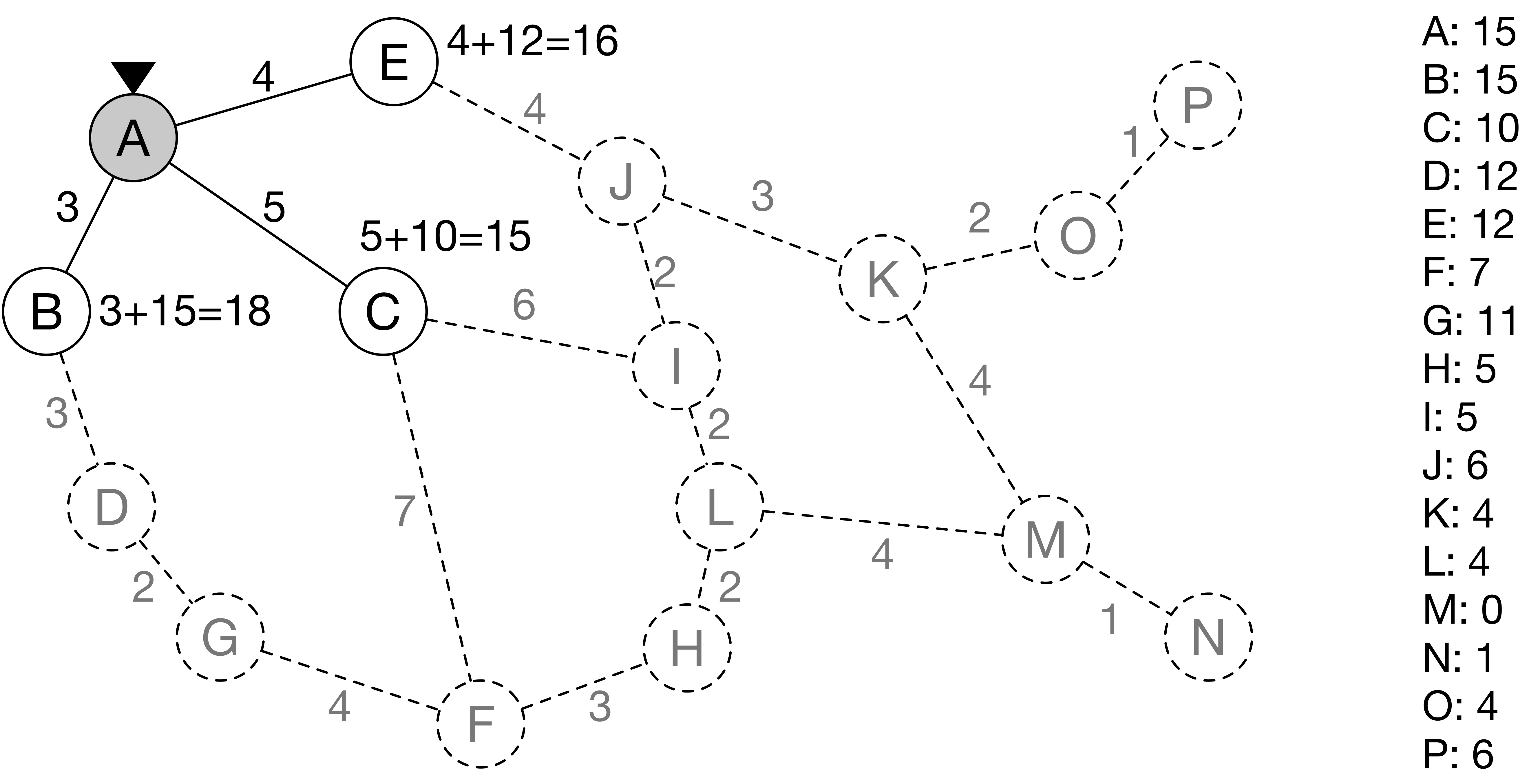
일단 노드 A에서 탐색을 시작한 컴퓨터는 인접한 링크 3개와 각 노드 3개에 대한 정보를 얻을 수 있다.
노드 B로 가는 길은 실제 거리가 3이고 노드 B에서 M까지의 직선 거리가 15이므로 총 거리는 18로 계산한다.
이 거리는 실제 거리가 아니지만, 현재 주어진 정보 하에서는 가장 설득력 있는 근사치이므로 이를 토대로 다음 탐색 지점을 고른다.
나머지 노드 C와 E에 대해서도 M까지의 거리 근사치를 계산하면 각각 15와 16이 된다.
가장 가까운 노드를 통해서 이동하는 것이 유리하므로 컴퓨터는 이제 노드 C로 이동한다.
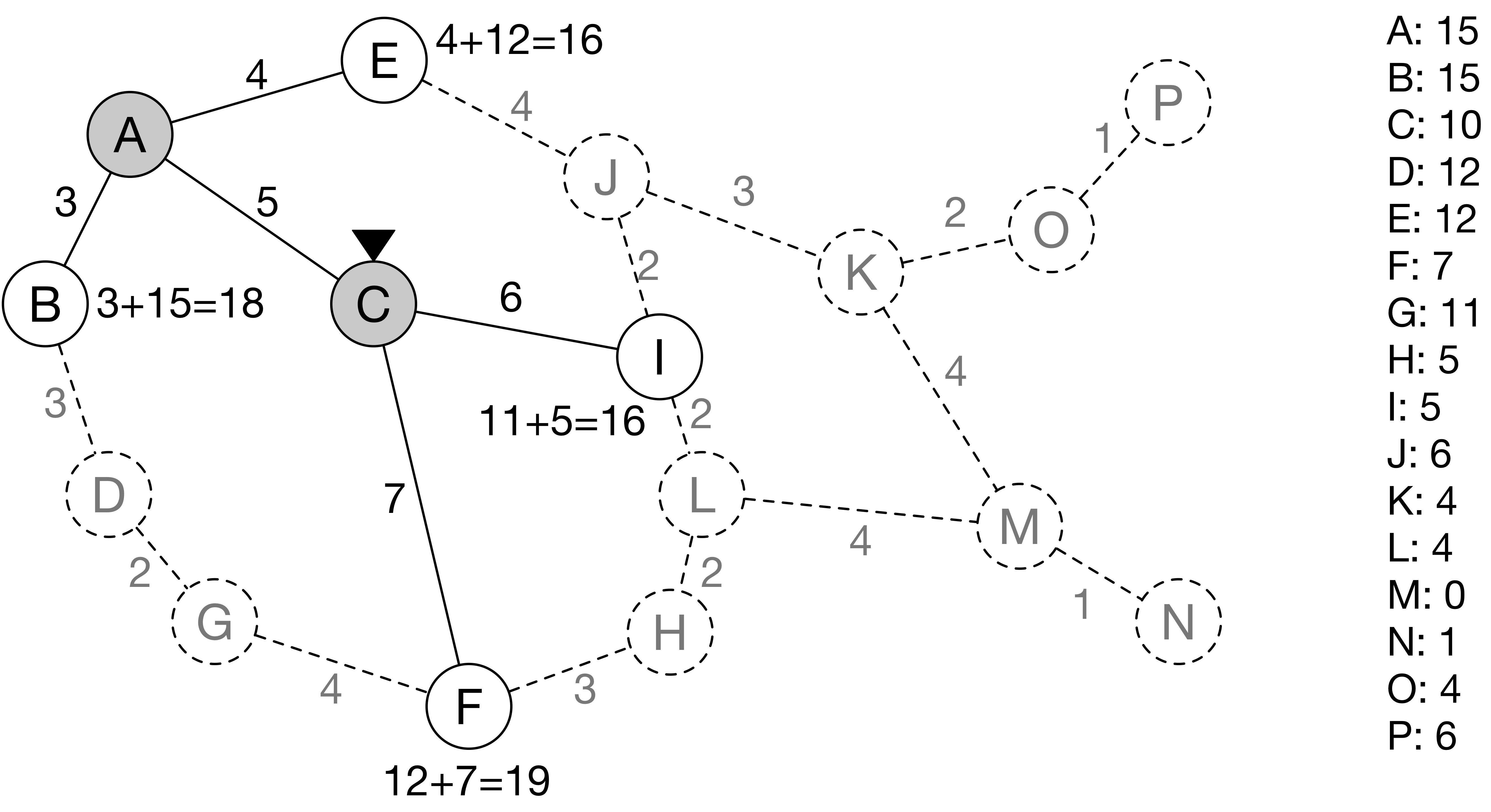
이제 노드 C로 이동한 컴퓨터는 인접한 링크와 노드 I, F의 정보를 알게 된다.
노드 I는 실제 거리 11(= 5 + 6)과 노드 M까지의 직선 거리 5를 더해 16의 거리를 갖는다.
노드 F는 실제 거리 12(= 5 + 7)와 노드 M까지의 직선 거리 7을 더해 19의 거리를 갖는다.
현재 컴퓨터가 갈 수 있는 노드는 B, E, F, I 총 4개이며, 이 중에서 최단 거리를 갖은 노드는 E, I다.
최단 거리 동점이 있으므로, 알파벳 순에 따라 다음에는 노드 E로 간다.
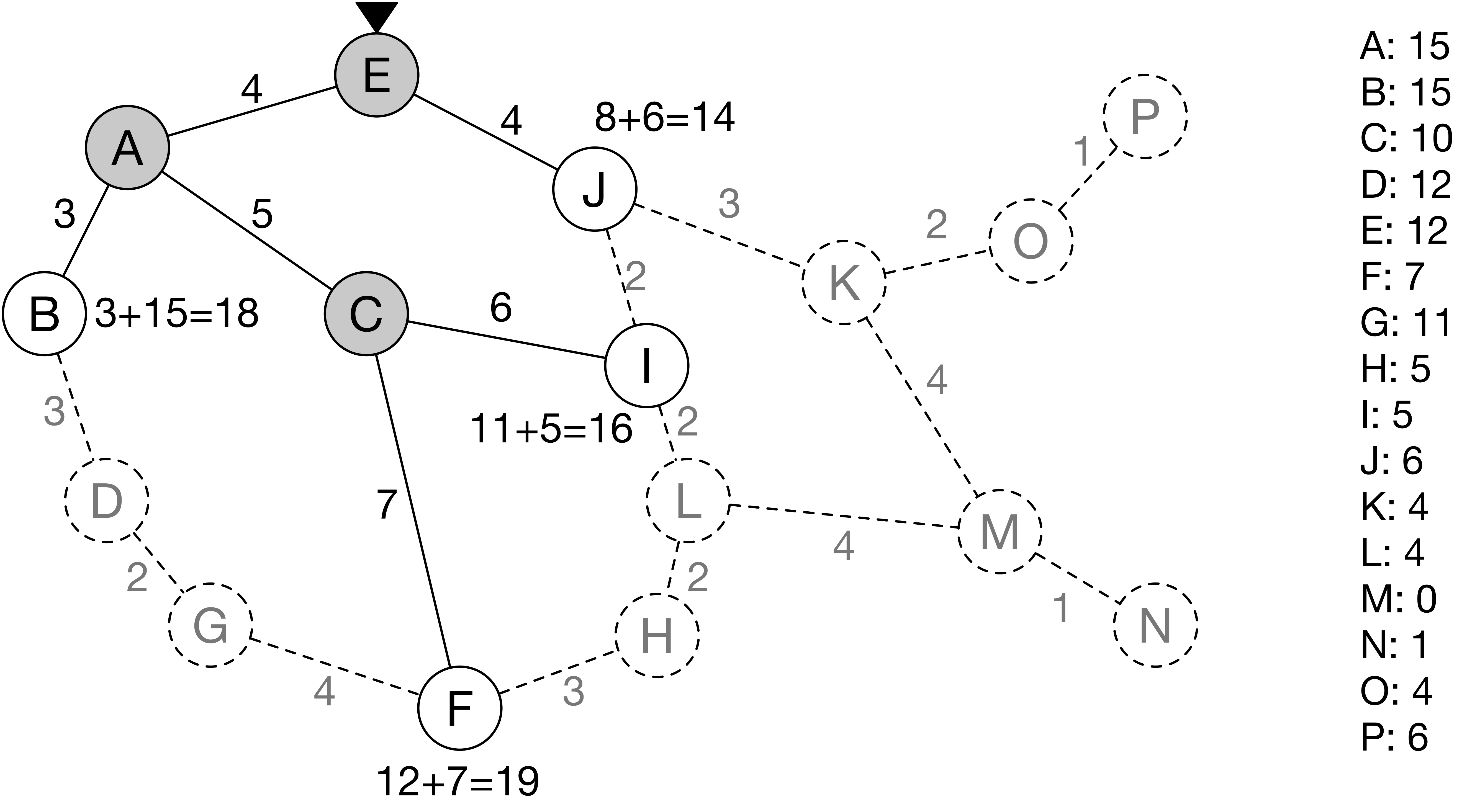
노드 E에 도착한 컴퓨터는 새로운 노드 J와 그 링크에 대한 정보를 알게 된다.
노드 J는 실제 거리 8과 노드 M까지의 직선 거리 6을 더해 14의 거리를 갖는다.
다음에 컴퓨터가 갈 수 있는 노드는 B, F, I, J 4개이며, 최단 거리는 노드 J이므로 이제 J로 간다.
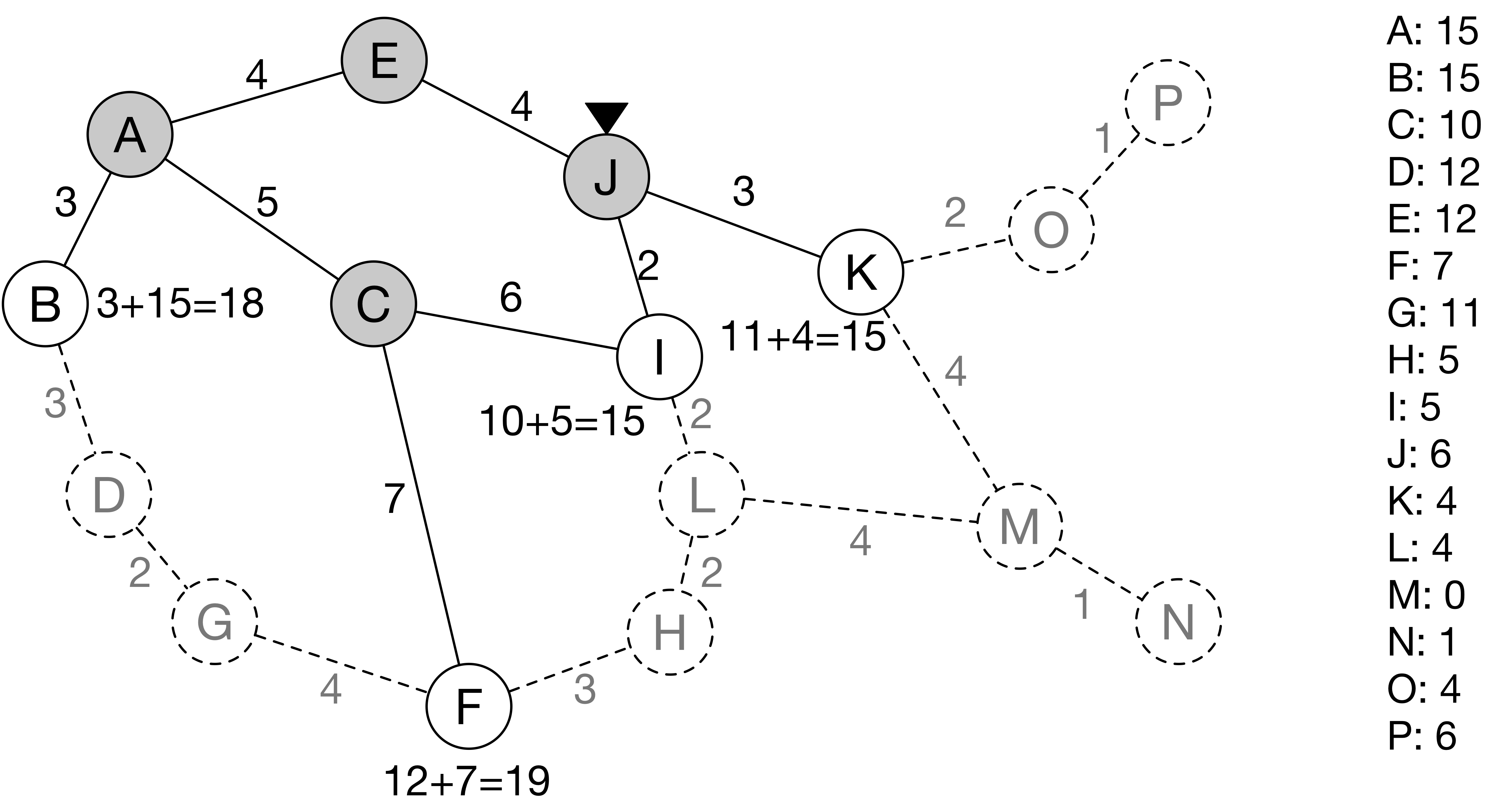
노드 J에 도착한 컴퓨터는 노드 K와 링크에 대한 정보를 얻는다.
노드 K는 거리 15를 갖는다.
노드 I는 새롭게 알게 된 링크의 실제 거리를 반영하여 거리가 15로 갱신된다.
다음으로 컴퓨터가 갈 곳은 노드 I다.
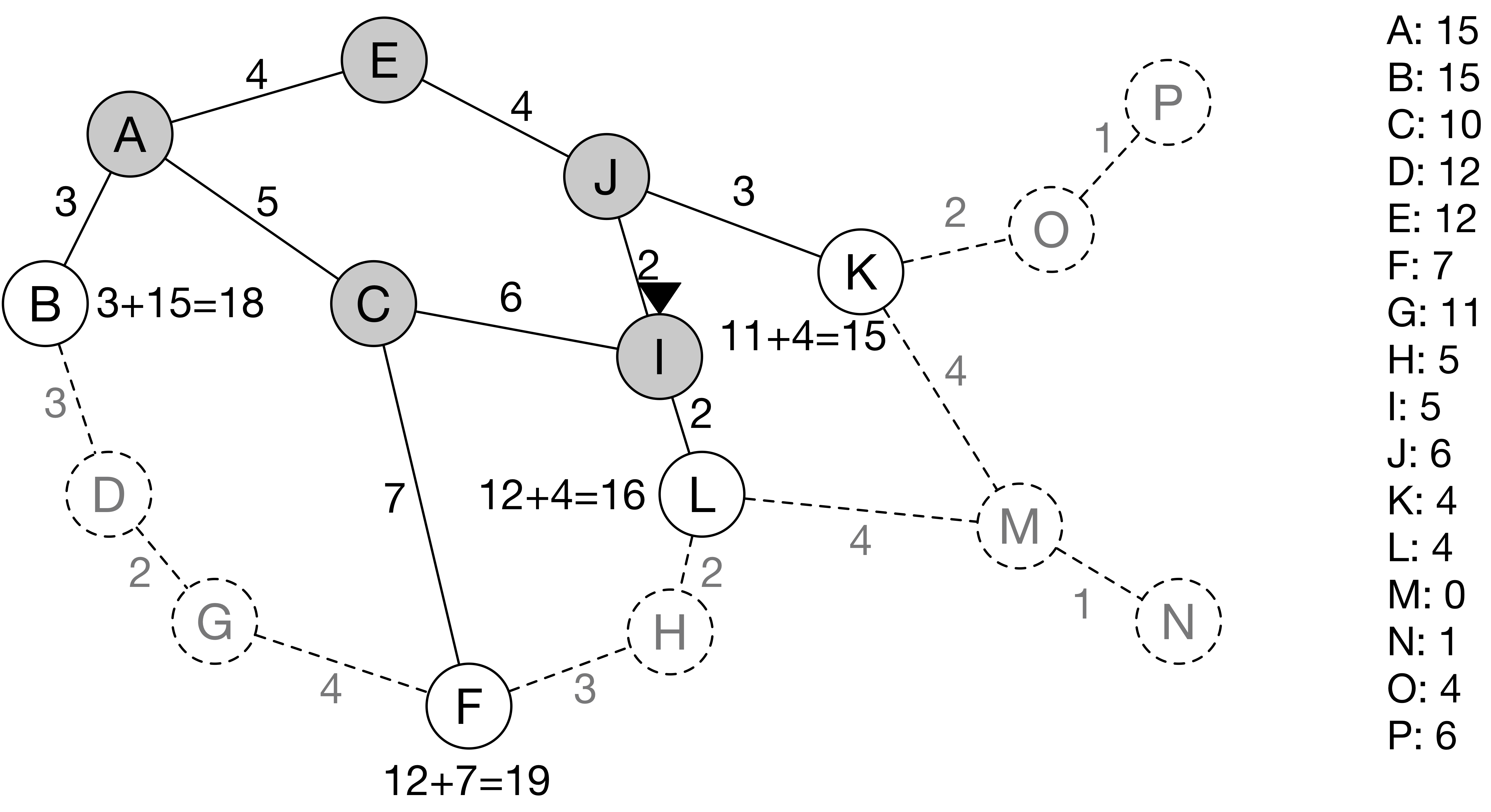
노드 I에 도착한 컴퓨터는 새로운 노드 L과 연결된 링크에 대한 정보를 알게 된다.
노드 L의 거리는 16이므로, 컴퓨터는 최단 거리 15를 갖는 노드 K로 간다.
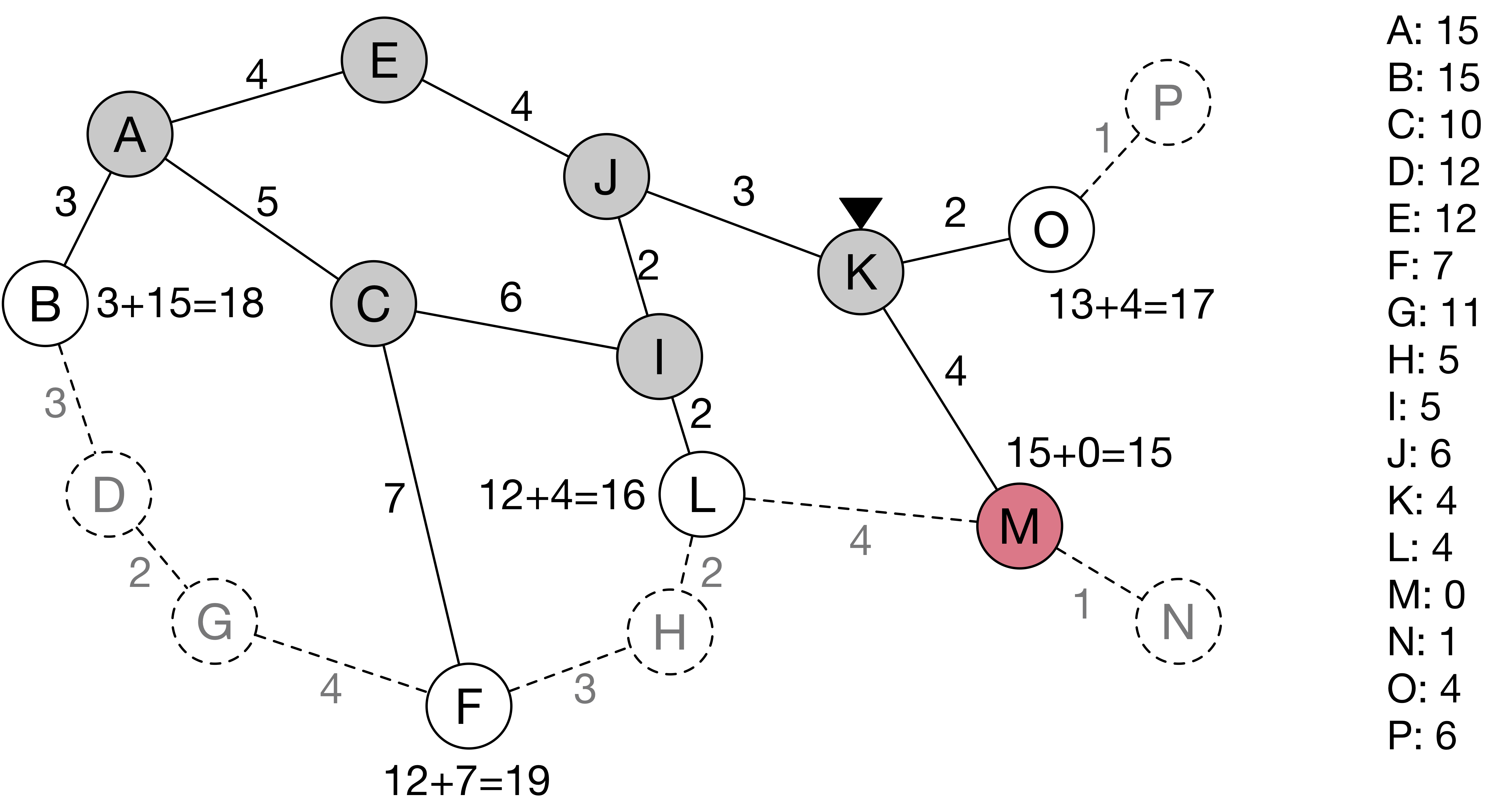
노드 K에 도착한 컴퓨터는 인접한 노드에 목표 지점인 노드 M이 있는 것을 발견하고 탐색을 마친다.
위의 탐색 과정에서 가장 주목할 점은 새로운 정보가 추가되면 이를 반영하여 현재의 정보를 갱신한다는 점이다. 이렇게 갱신된 정보를 바탕으로 다음 행동을 결정하기 때문에 효율적인 탐색이 가능하다. 컴퓨터가 특정 노드를 방문하는 것을 GA Reporting API에 호출하는 것과 같다고 생각한다면, API 호출의 결과를 통해 현재 정보를 갱신하고 다음 API 호출을 합리적으로 결정할 수 있을 것이다.
그래프 탐색을 이용한 GA Reporting API 호출
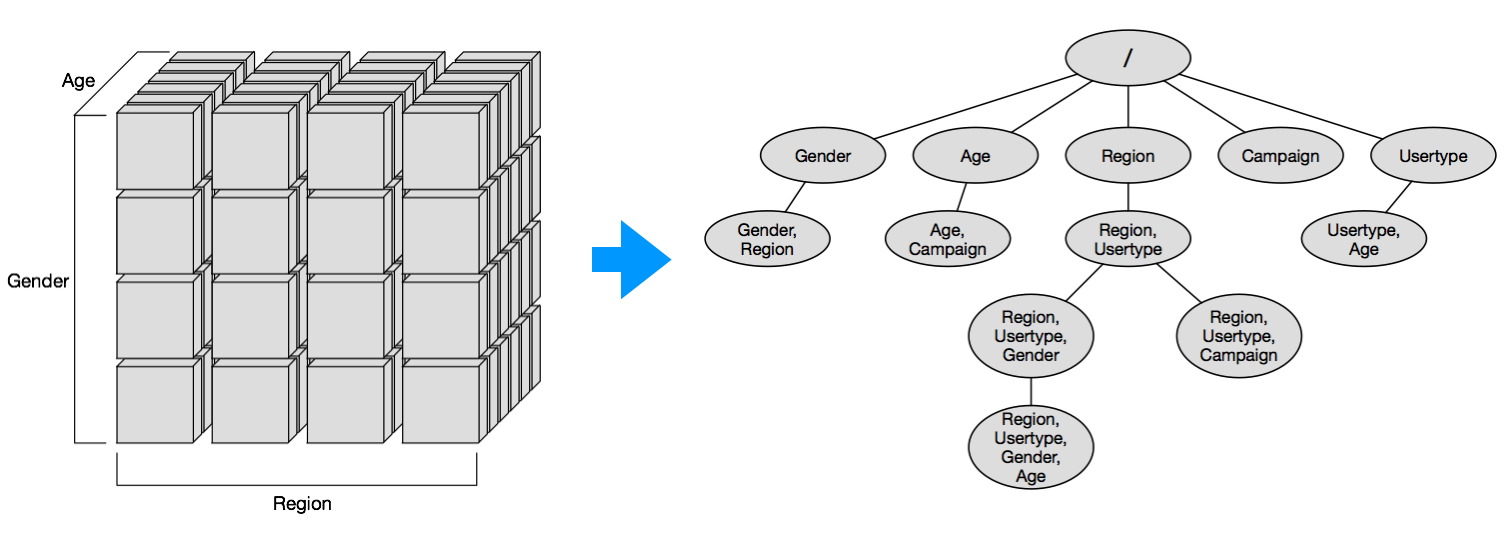
다차원 조합에 대한 탐색을 그래프 구조를 옮기면, 그래프의 각 노드는 차원 조합으로 구성된다. 처음에는 아무런 차원이 없는 노드에서 탐색을 시작하고, 이후에 차원을 하나씩 더해 점점 복잡한 차원 조합으로 노드를 확장한다. 각 노드에 방문을 한다는 것은 GA Reporting API에 해당 노드의 차원 조합으로 데이터를 요청하는 것이다. 호출의 결과로 세션(S)이나 매출(R) 정보를 받으면 이를 통해 정보를 갱신하고 다음 호출 대상을 선택한다.
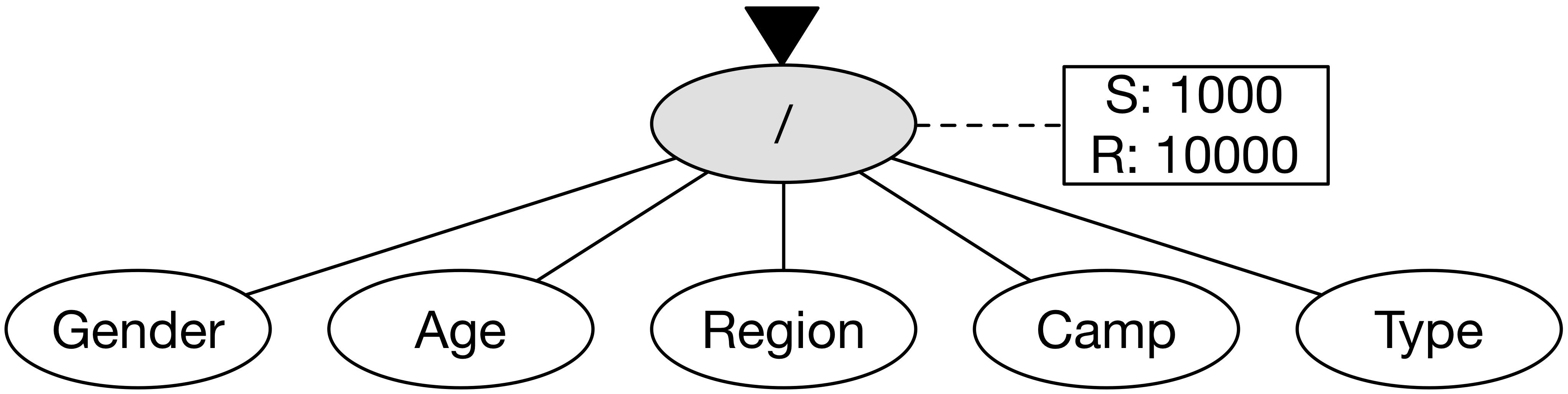
우선 아무런 차원이 없는 루트 노드에 방문을 한다.
이 결과로 세션 1000, 매출 10000의 정보를 얻었다.
해당 기간에 이 웹 사이트는 총 세션이 1000, 총 매출이 10000이라는 것을 알 수 있다.
호출 결과와 함께 다음에 방문할 수 있는 노드 5개를 새롭게 얻는다.
설명의 편의상 Gender, Age, Region, Camp, Type 총 5개의 차원만 있다고 가정한다.
차원 조합이 하나인 5개의 노드는 우선 하나씩 방문하도록 한다.
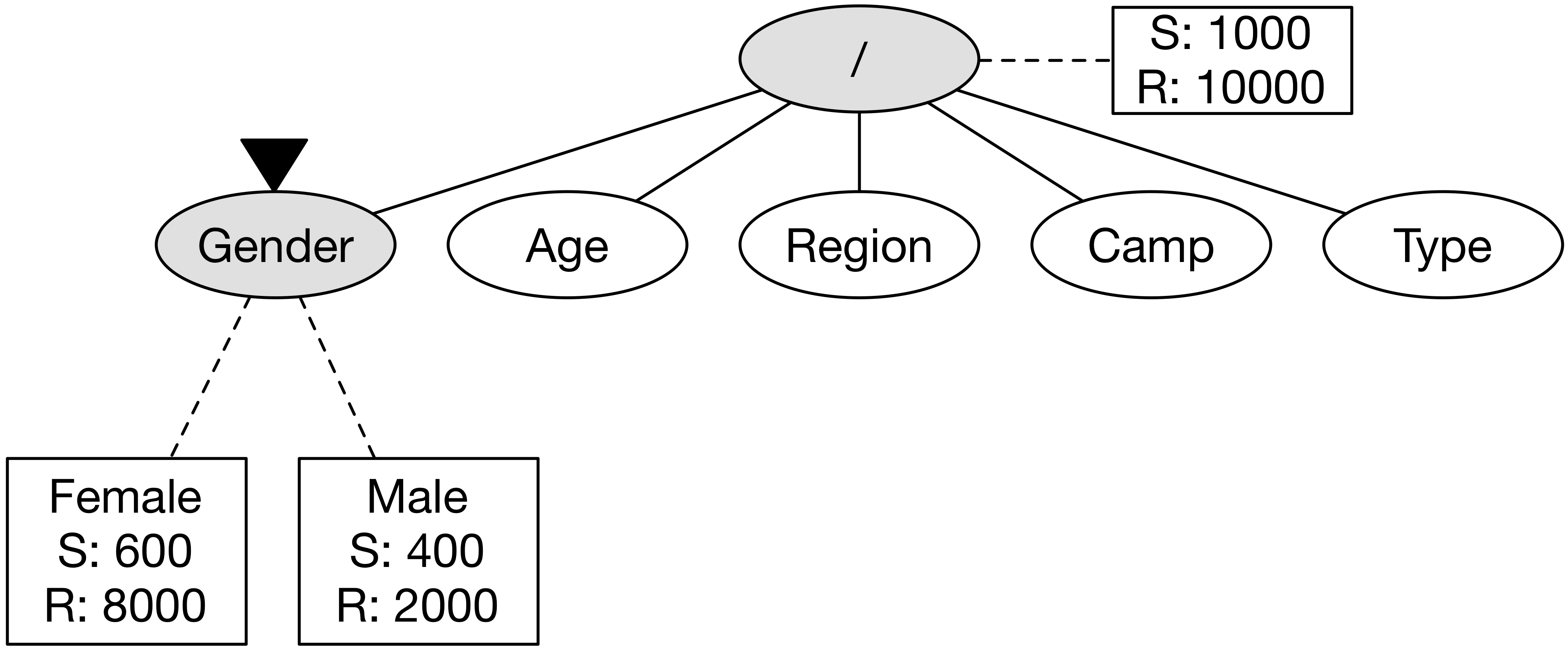
먼저 노드 Gender에 방문한다.
GA Reporting API에 Gender 차원 조합으로 호출을 하면 성별 기준에 의한 2개의 셀을 얻을 수 있으며, 각각 세션 600, 매출 8000과 세션 400, 매출 2000의 값을 갖는다.
현재 탐색의 기준이 매출이라면 가장 높은 매출을 기록한 Female의 8000을 이용해서 총 매출 비율 0.8(= 8000 / 10000)을 계산한다.
이 0.8이라는 숫자는 Best-first search에서 우선 순위로 사용한다.
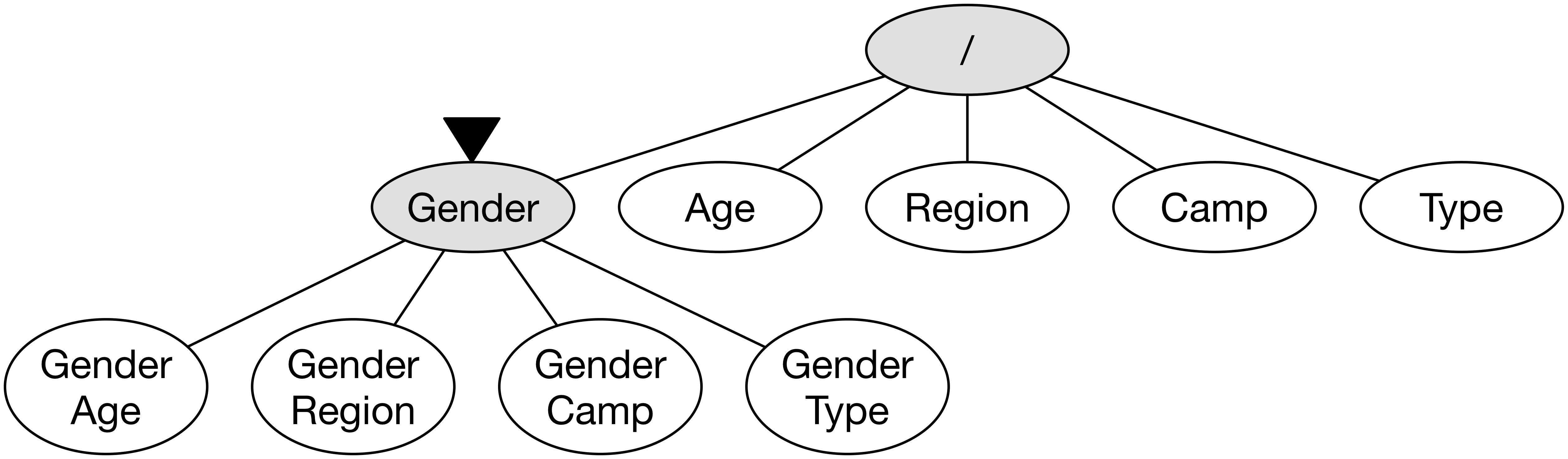
노드 Gender에 방문한 후에는 이 노드와 연결된 다른 이웃 노드로 확장을 해야한다.
추후에 방문할 후보군을 생성하는 과정인데, 이는 다른 차원과의 조합을 통해 구성한다.
즉, Gender 차원에 추가로 Age, Region, Camp, Type를 조합해서 총 4개의 새로운 차원 조합을 만든다.
이는 각각 새로운 노드가 되며, 추후에 방문하게 된다.
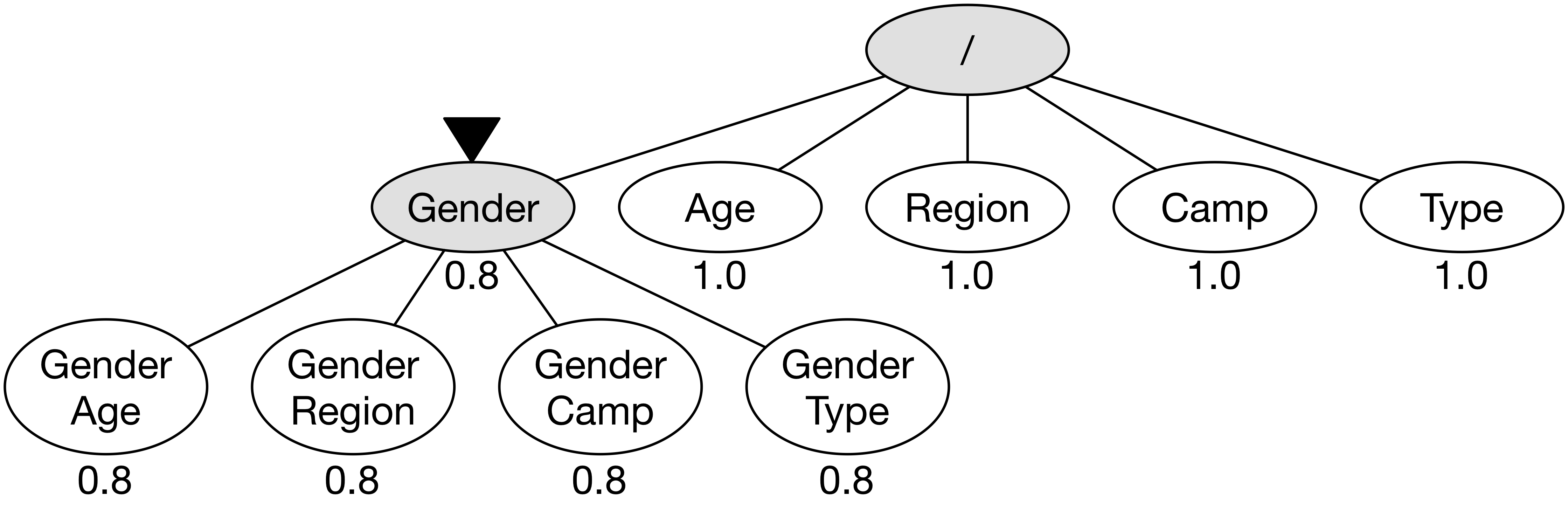
노드 방문의 우선 순위를 결정하기 위해서 노드마다 점수를 부여한다.
아직 아무런 정보가 없는 Age, Region, Camp, Type 4개 노드는 1.0을 임의로 부여한다.
노드 Gender의 경우에는 이미 방문하여 정보가 있으므로 방금 전에 계산한 0.8을 점수로 기록한다.
노드 Gender에서 확장된 (Gender, Age), (Gender, Region), (Gender, Camp), (Gender, Type) 4개의 노드는 각 부모 노드의 점수를 곱해서 계산한다.
예를 들어 (Gender, Age)의 경우에는 Gender 0.8과 Age 1.0을 곱한 0.8을 우선 순위 점수로 기록한다.
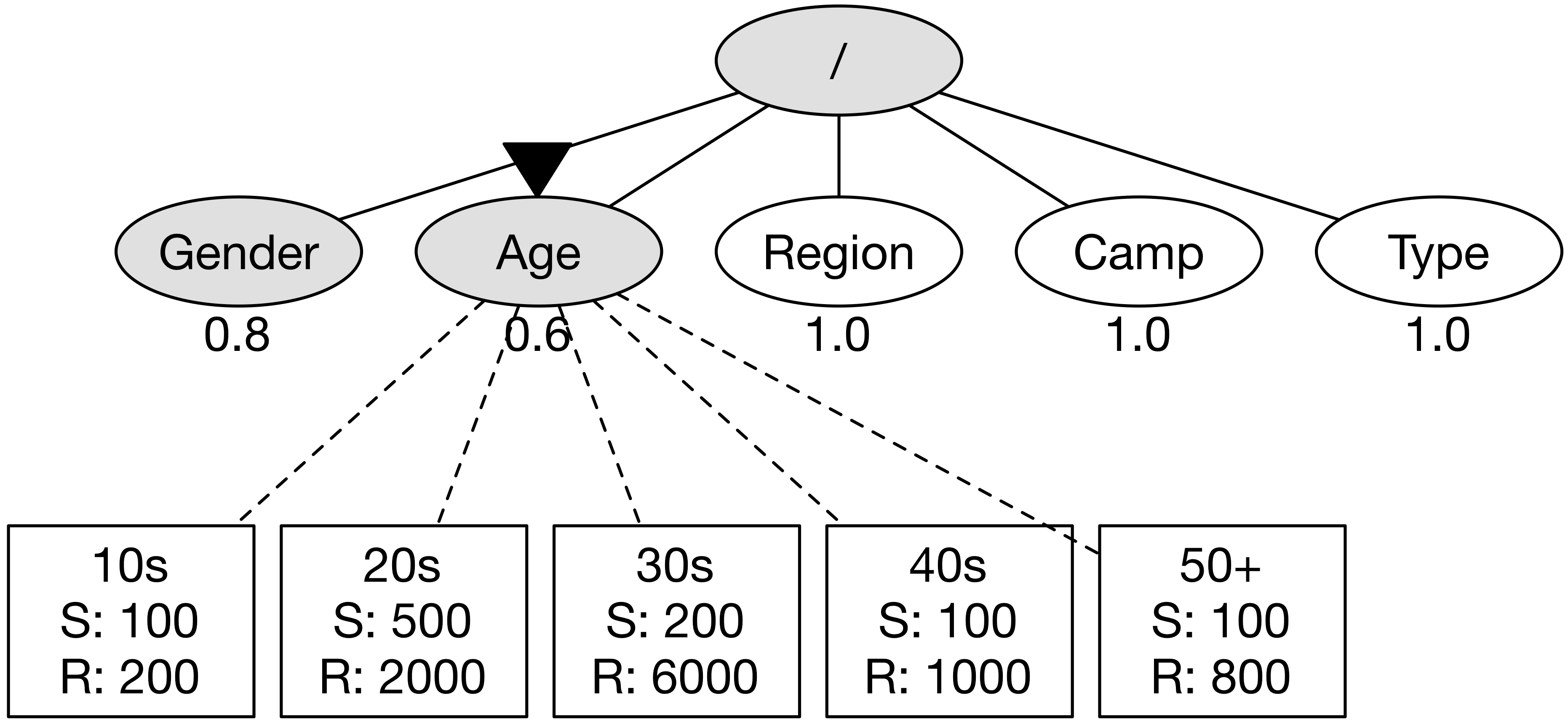
우선 순위가 1.0으로 가장 높은 노드들 중에서 Age에 먼저 방문한다.
노드의 차원을 기준으로 GA Reporting API를 호출하면 각 나이 그룹에 대한 정보를 얻을 수 있다.
30s의 매출이 6000으로 가장 높으므로 노드 Age의 우선 순위 점수는 0.6으로 갱신한다.
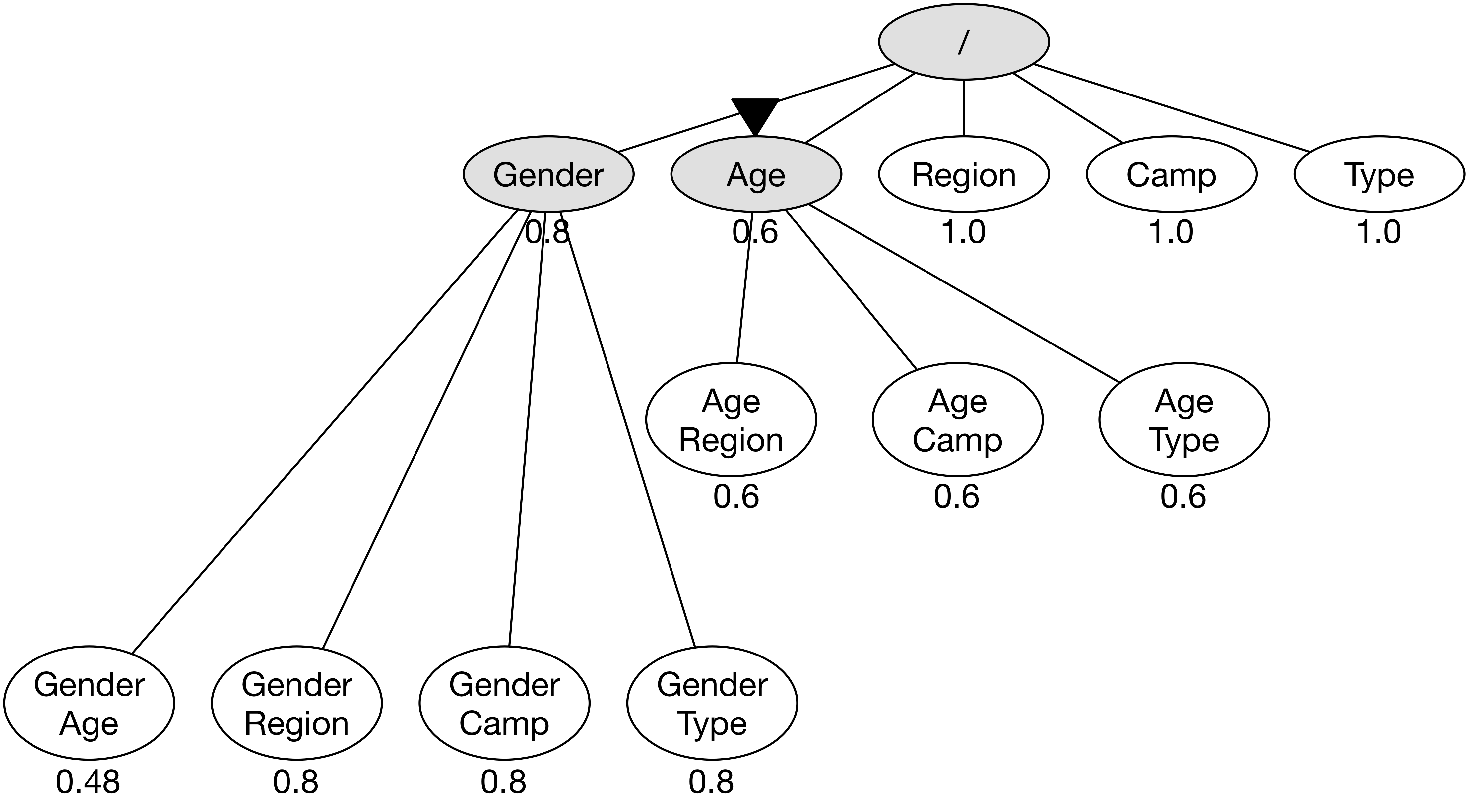
노드 Age의 우선 순위 점수가 0.6으로 갱신되었으므로 Age와 관련이 있는 모든 노드의 우선 순위 점수를 갱신한다.
노드 (Gender, Age)의 경우 우선 순위 점수가 0.8이었으나 갱신 후에는 0.48(= 0.8 * 0.6)로 기록한다.
노드 Age에서도 마찬가지로 다른 차원과의 조합을 통해 새로운 노드로 확장한다.
결과적으로 (Age, Region), (Age, Camp), (Age, Type) 총 3개의 노드가 추가되었다.
아울러 새로 추가된 노드의 우선 순위 점수도 같은 방식으로 기록한다.
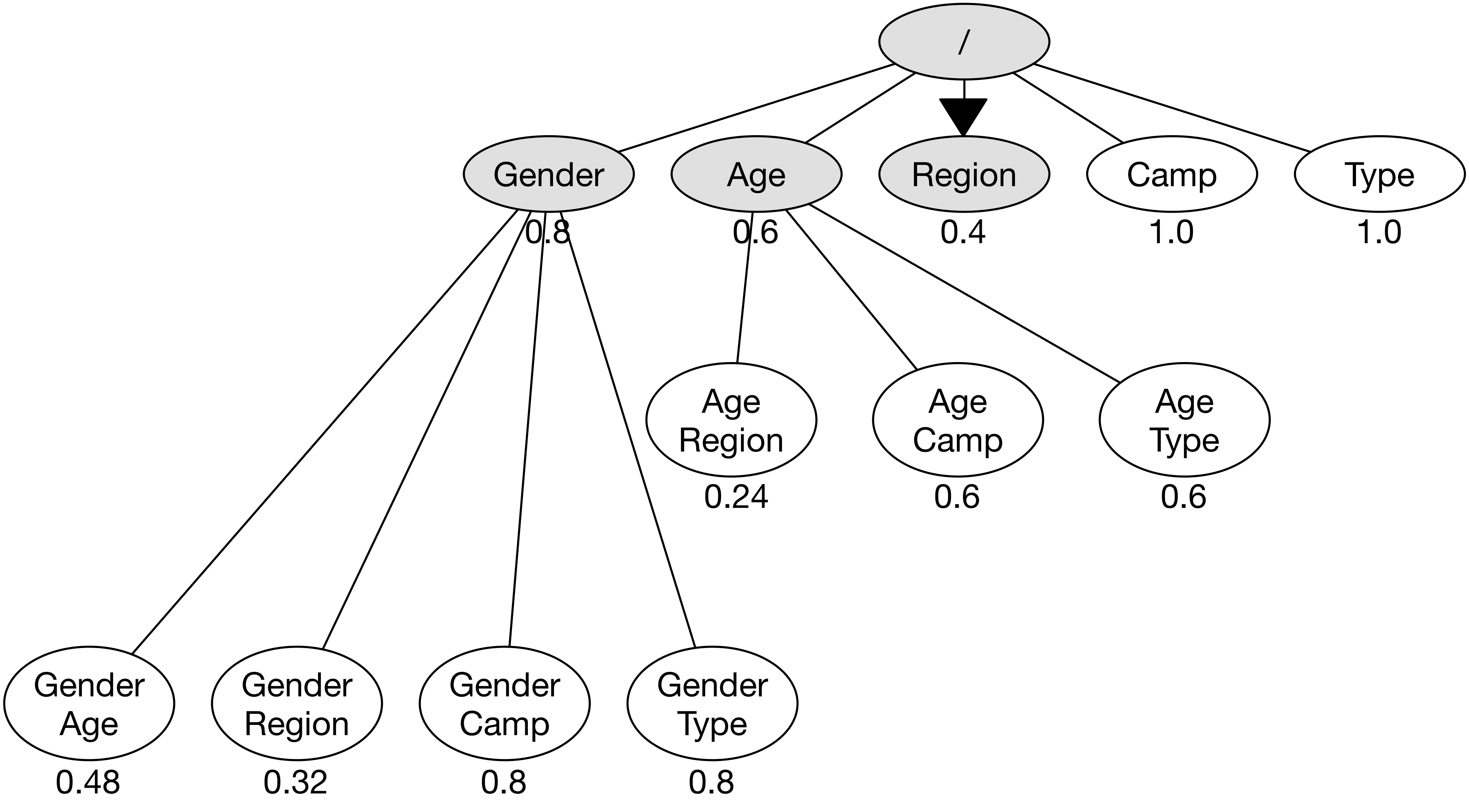
우선 순위가 가장 높은 노드 중에서 Region에 방문한다.
GA Reporting API 호출 결과, 매출이 4000인 셀이 있었으며 Region의 우선 순위 점수는 0.4로 갱신된다.
아울러 Region과 관계있는 노드의 우선 순위 점수도 함께 갱신한다.
(Gender, Region)과 (Age, Region)의 점수가 갱신되었다.
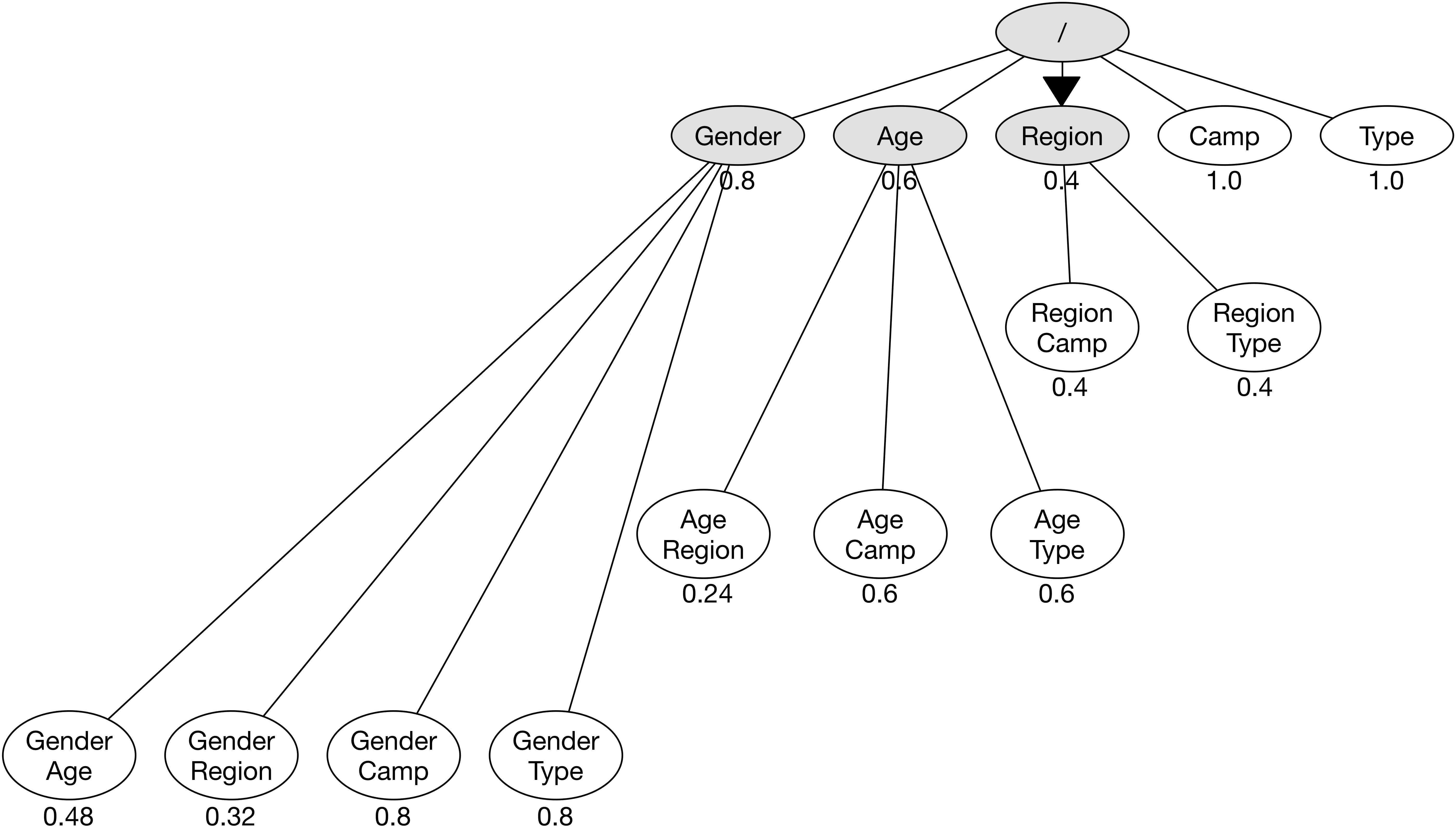
노드 Region을 확장하여 새로운 노드 (Region, Camp), (Region, Type)을 만든다.
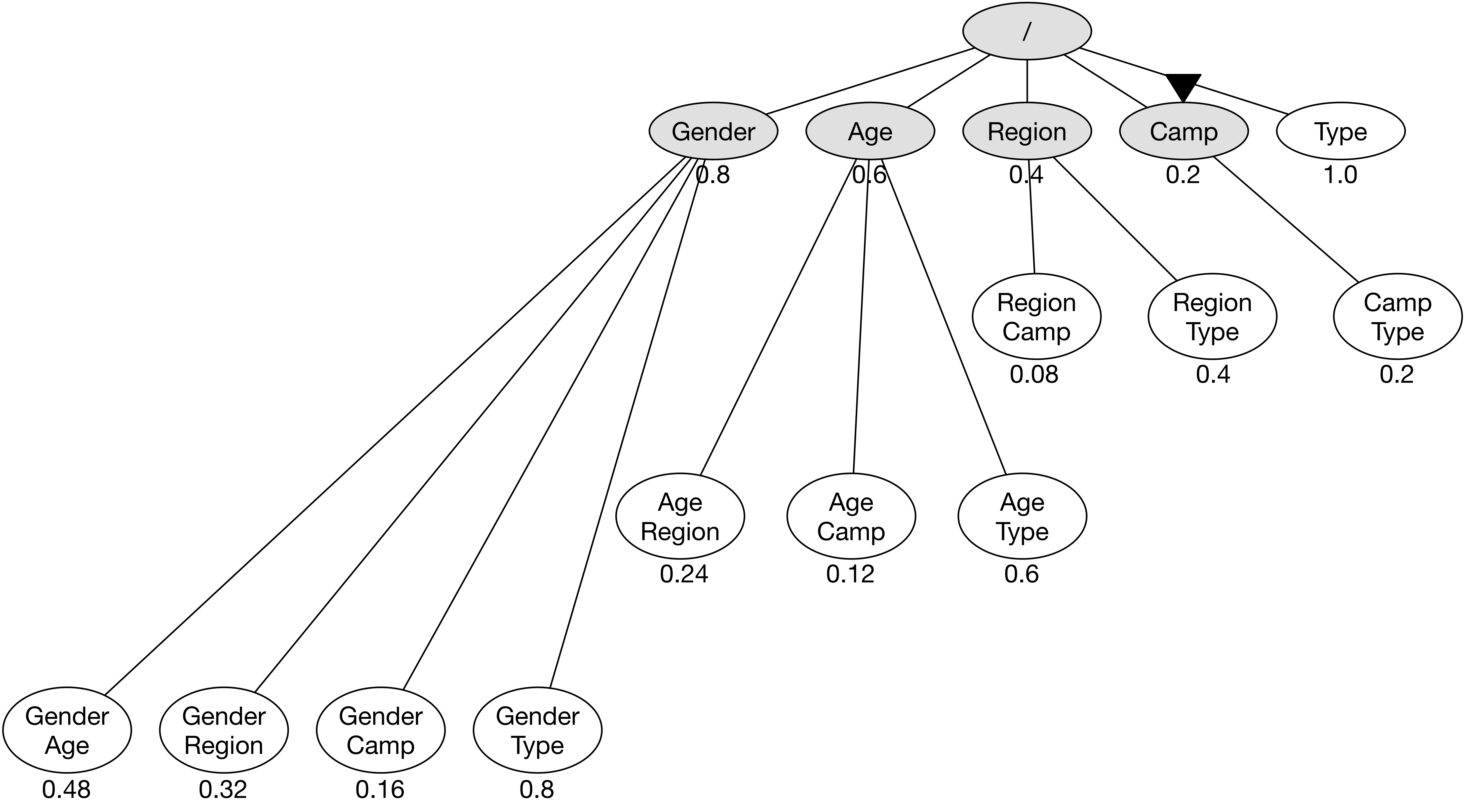
우선 순위가 높은 노드 Camp에 방문하고, 호출 결과로 우선 순위 점수를 0.2로 갱신한다.
이와 관련한 다른 노드의 우선 순위 점수 역시 함께 갱신한다.
아울러 노드 Camp에서 추가로 노드 (Camp, Type)을 확장한다.
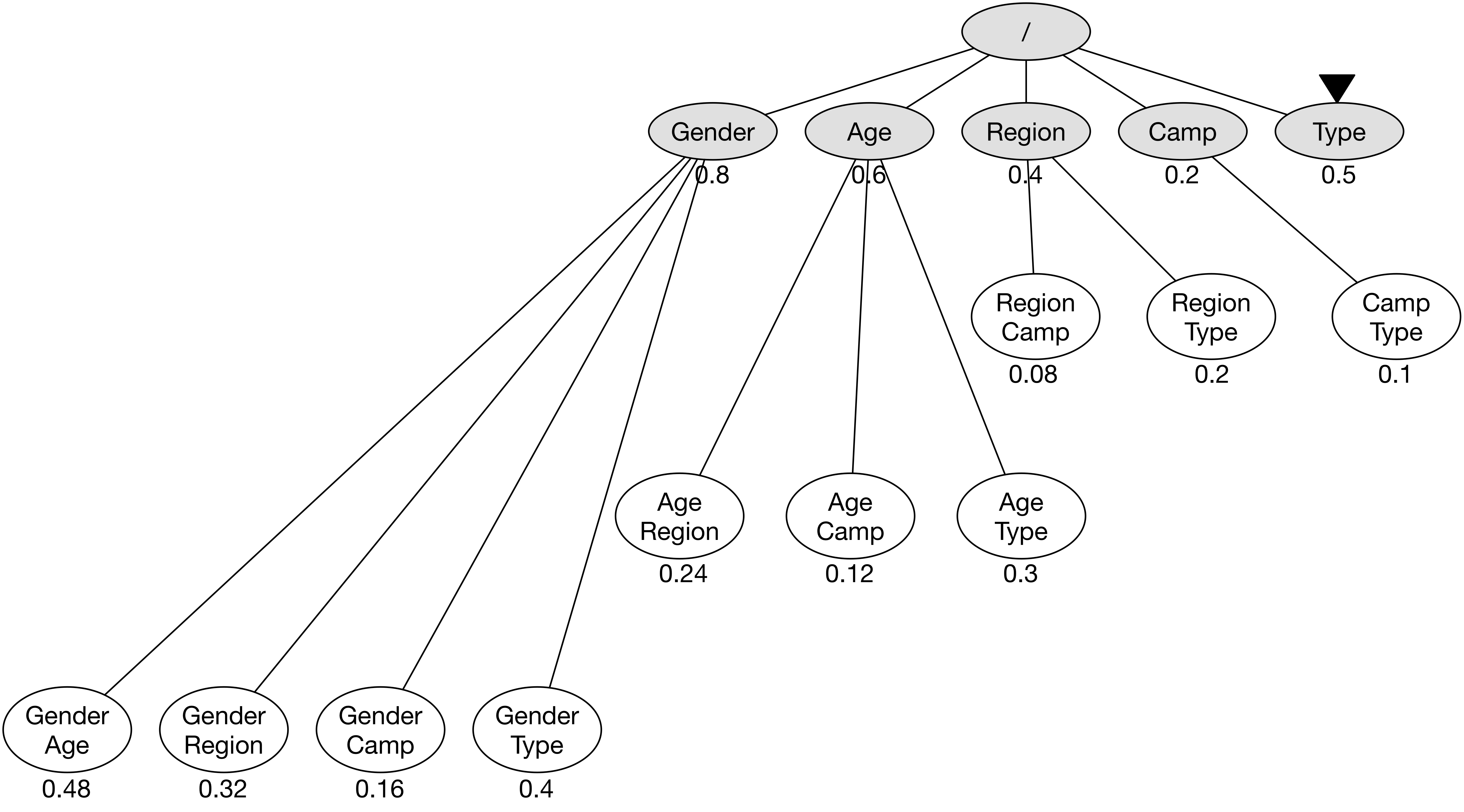
가장 우선 순위 점수가 높은 노드 Type에 방문하여 호출 결과로 우선 순위 점수를 0.5로 갱신한다.
노드 Type과 연관된 다른 노드의 우선 순위 점수도 모두 갱신한다.
차원이 단 하나 뿐인 노드의 방문을 모두 마쳤기 때문에 위의 그래프 구조는 기본적인 우선 순위 점수를 모두 갱신하였다.
지금까지와 마찬가지로 가장 우선 순위가 높은 노드를 먼저 방문하고 GA Reporting API 호출 결과로 점수를 갱신하는 작업을 반복한다.
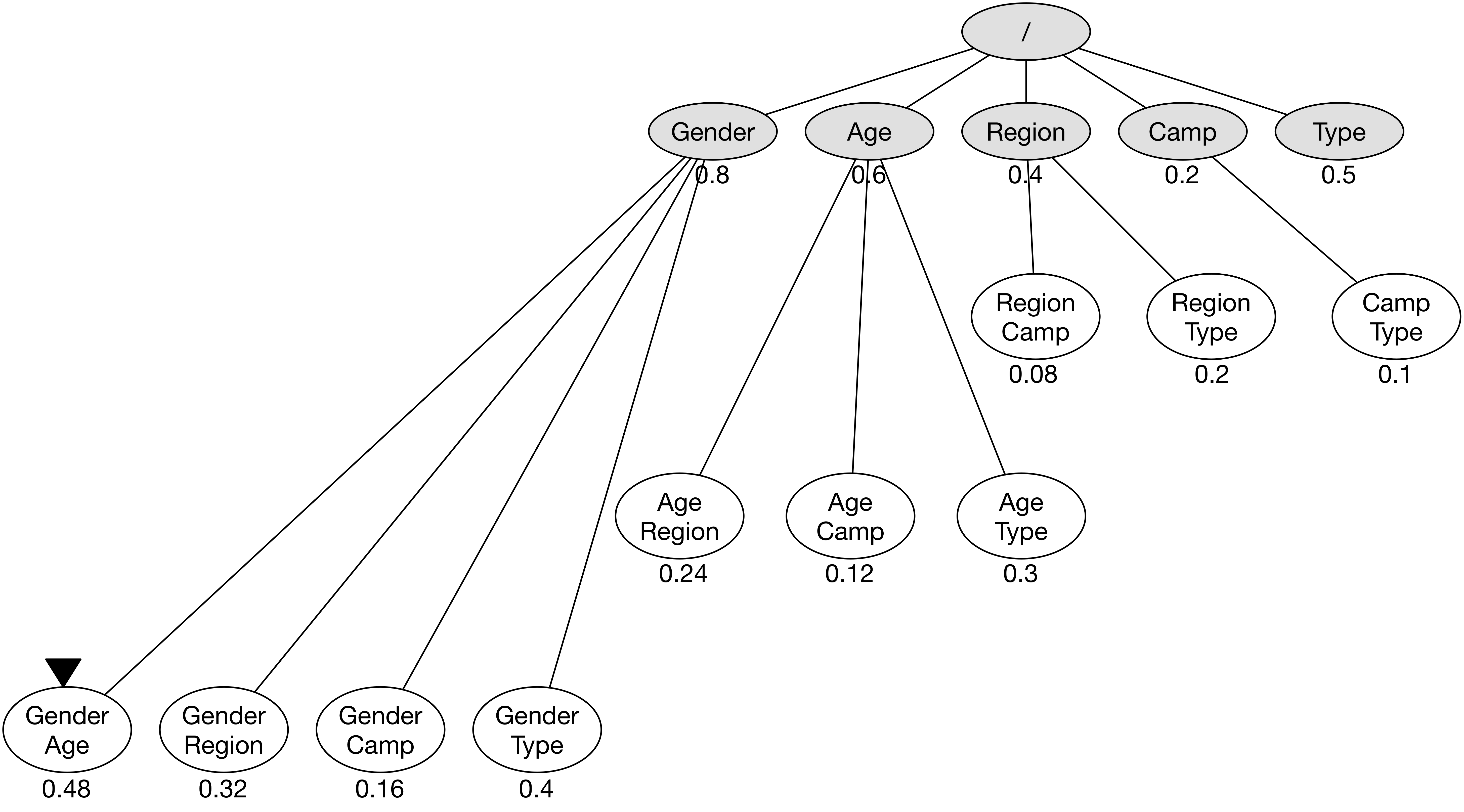
이제 가장 우선 순위가 높은 노드는 (Gender, Age)이므로 해당 노드에 방문하여 차원 조합을 이용해 API를 호출한다.
길 찾기 문제와 다른 점은 마지막에 도착해야할 목표 노드가 없다는 점이다. 어차피 GA Reporting API의 제약 때문에 탐색 공간 전체를 모두 탐색하는 것은 불가능하다. 따라서 탐색 기준에 가장 부합하는 차원 조합의 셀을 많이 저장하는 것이 이 탐색의 목표다. 주어진 제약 조건 내에서 최대한 탐색 기준에 맞는 차원 조합을 탐색하고, 그 결과를 이용해 원하는 고객 세그먼트를 발견하는 것이 탐색의 목적이다.
탐색 효율
약 13만 개의 API 호출을 며칠동안 실행하면 전체 데이터를 얻을 수 있다. 이렇게 얻은 전체 데이터와 250 번의 API 호출만으로 얻은 데이터를 비교하면 아래와 같다.
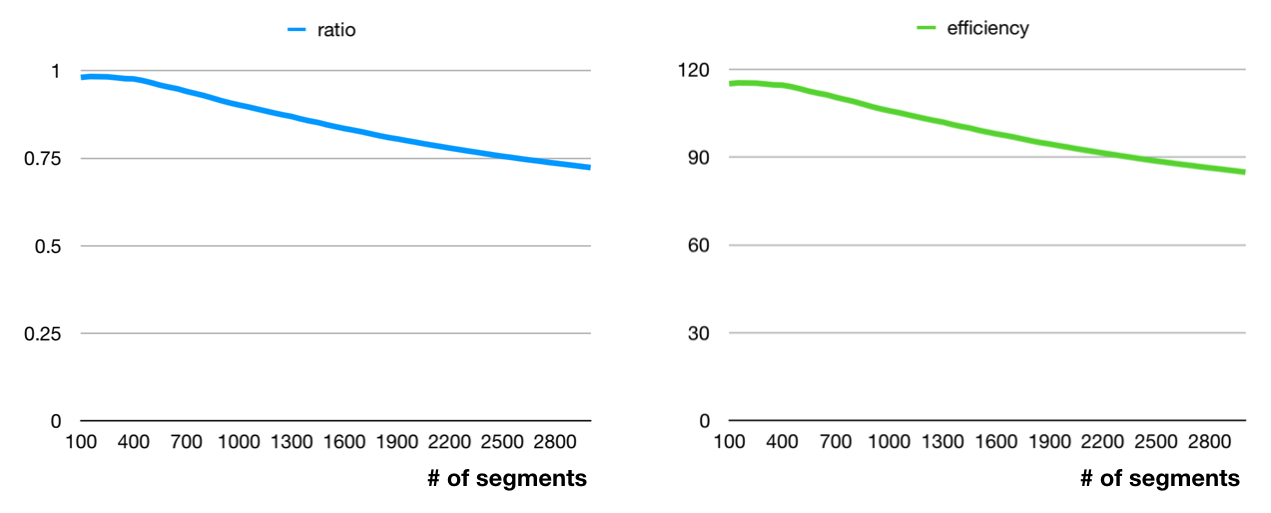
그래프의 가로축은 원하는 세그먼트의 수를 의미한다. 왼쪽의 그래프는 전체 데이터 대비 실제로 찾은 고객 세그먼트 비율을 의미한다. 최고 효율의 고객 세그먼트 100개를 찾는다면 그래프 탐색을 이용한 방법이 전체 탐색 대비 약 99%의 세그먼트를 찾을 수 있었다. 만약 1000개의 고객 세그먼트를 찾는다면 그래프 탐색을 이용한 방법이 전수 대비 약 88%의 세그먼트를 찾아낸다. 즉, 전체를 모두 보지 않아도 그래프 탐색을 이용해 똑똑하게 찾는다면 대부분의 유용한 정보를 찾을 수 있다.
오른쪽 그래프는 호출 하나 당 효율 차이를 나타낸 것이다. 전체 탐색이 API 호출 당 1의 정보를 찾았다면, 그래프 탐색은 약 120에서 90의 정보를 찾을 수 있었다. 단순하게 비교하면 그래프 탐색을 통해서 90~120배로 효율적인 API 호출을 할 수 있다.
결론
구글 애널리틱스를 활용하고 있는 웹 사이트라면 고객 세그먼트 분석을 위해서 많은 비용과 시간을 투자할 필요가 없다. 이미 구글 애널리틱스가 수집하고 있는 데이터를 똑똑한 방법으로 호출하면 아주 유용한 정보를 쉽게 찾을 수 있다. Best-first search를 금광 캐기에 비유하자면 금이 있을 것 같은 곳을 집중적으로 파보는 것이다. 모든 광산을 다 파서 확인하는 것은 너무 비효율적이다. 한 번에 조금씩 파면서 어떤 곳에 금이 있을지 정보를 갱신하며 똑똑하게 캐면 훨씬 적은 노력으로도 귀중한 정보를 얻을 수 있다.
참고
- 관련 발표 - PyCon KR 2017: Best-first search를 이용한 다차원 큐브 탐색
- 참고 도서
- Artificial Intelligence: A Modern Approach CH3.5 Informed (heuristic) search strategies
- Artificial Intelligence: A Modern Approach CH3.6 Heuristic functions